This is the third and final story in our investigation trilogy titled Facebook Algorithmic Factory, created with the intention to map and visualise a complex and invisible exploitation process hidden behind a black box of the World’s largest social network.
The three stories are exploring four main segments of the process:
Data collection – Immaterial Labour and Data harvesting
Storage and Algorithmic processing – Human Data Banks and Algorithmic Labour
Targeting – Quantified lives on discount
The following map is one of the final results of our investigation, but it can also be used as a guide through our stories, and practically help the reader to remain in the right direction and not to get lost in the complex maze of the Facebook Algorithmic Factory.

Targeting : Quantified liVes on discount
“In their now classic study of traditional media, Manufacturing Consent, Herman and Chomsky explain the basic business model of newspapers as being the production of an audience for advertising. Their analysis suggests the counterintuitive notion that publishers’ main product is not the newspaper, which they sell to their readers, but the production of an audience of readers, which they sell to advertisers. In short, the readership is their product.”
The difference between Facebook and traditional media is that on Facebook there is no readership in general, but the an algorithmic labour and production within the Facebook Factory which allows them to profile and sell each user as an different product.
In order to map this process we examined the structure, categorisation and targeting methods available to advertisers through Facebook. There are 3 main categories of targeting options, user profiling based on basic information (location, age, gender and language), detailed targeting (based on users’ demographics, interests and behaviours) and connections (based on specific kind of connection to Facebook pages, apps or events). Every user is basicly profiled and tagged with the use of those three methods and is being offered as a target for advertising. Facebook’s revenue ($ 17.93bn in 2015) directly depends on the user profiling quality. The more accurate the user profiles are, the better product offered to advertisers they become. The ultimate product of Facebook’s surveillance economy is a deep insight into your interests and behaviour patterns, exact knowledge who you really are and prediction how you will eventually behave in the future, packed in user profiles.
Connecting the dots
It is important to say that the left side of the presented visualisations is based only on our assumptions. According to the list of different types of data collected by Facebook and different algorithms, databases and meta structures that we featured in previous segments of our research, we tried, using our logic to make conclusions and to relate different targeting methods with matching data sources and algorithms.
For example, if on the Targeting side we have targeting based on <user gender>, we can easily relate, connect this with <gender> information provided by the user in the Profile Information section on the Input side of the graph. But, in most cases, it is not as simple as that.

Basic targeting is mostly based on information provided by users in the Profile information section, except location that can be determined in multiple ways using the digital footprint of our devices. Targeting based on Connections can be based on data from the Social Graph and Action data.
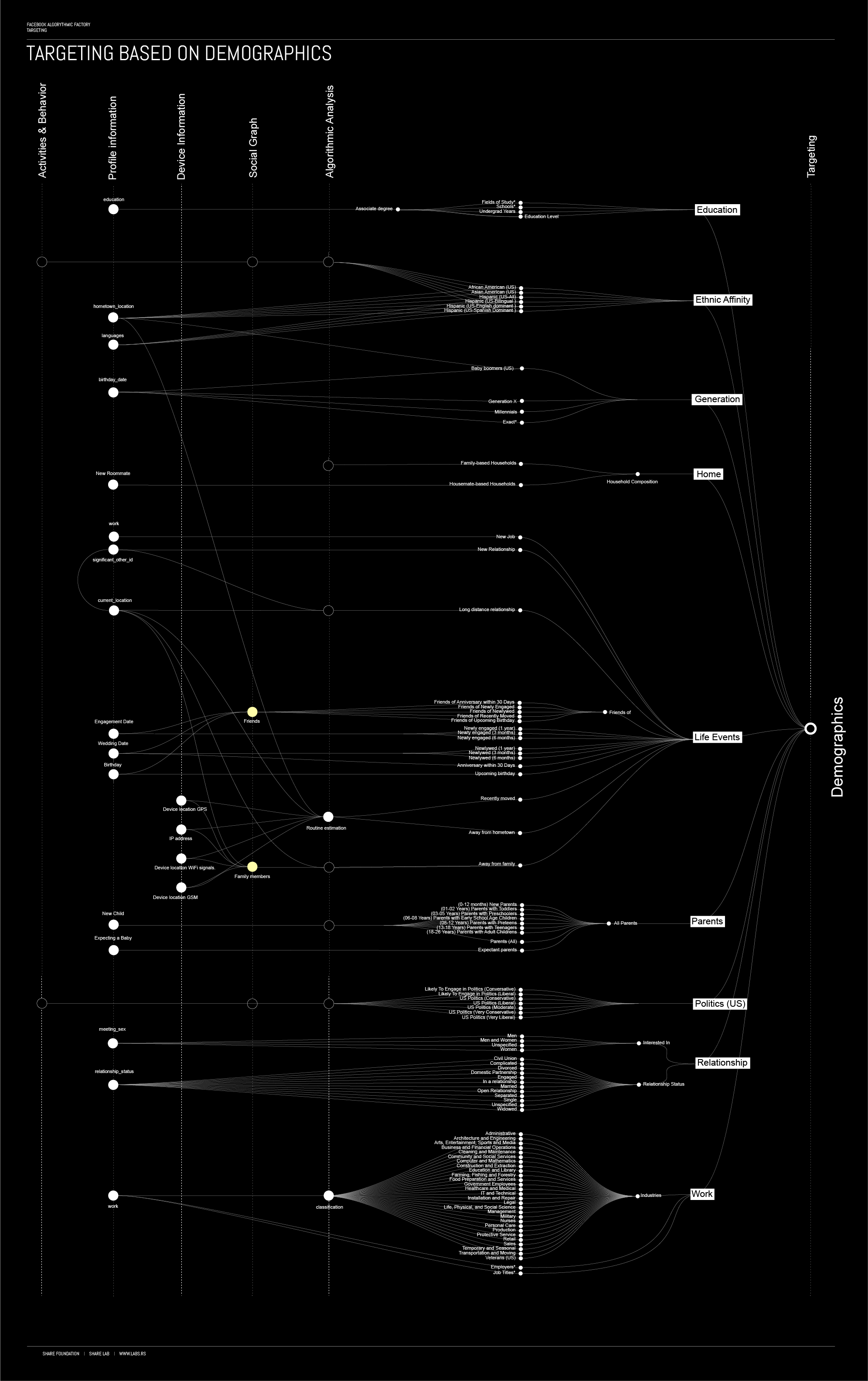
Our assumption is that Targeting based on Demographics is mostly based on profile information, but there are few interesting cases that can be potentially subject of further investigation.
For example, Facebook offers among other categories, targeting based on ethnic affinity and as one of the option, they offer targeting of US Hispanic, African-American and Asian-American clusters. They have explained that this is based on actual users who are interested in or will respond well to Hispanic content, based on how they use Facebook and what they share on Facebook. To be able to cluster users into this kind of categories, they probably use analysis of users’ social connections in the social graph. However, a legitimate question to Facebook at this point would be, how African-Americans use Facebook in a different manner that can be tracked compared to Asian-Americans?
Another interesting and potentially unethical targeting method is something that they call targeting based on Life events. Here you can be targeted not only based on your behaviour but based on the behaviour and actions of you friends. So, for example you can be a target of advertising if the people in your social network are engaged in certain topics. This is a clearly great example of the power of the social graph analysis.
An excellent example of how hard it is to avoid targeting on Facebook, if we consider for example the Parents category, is an experiment from a Princeton sociology professor, Janet Vertesi who tried to see if it is possible to prevent Facebook detect she was pregnant.
In light of the recent discussions related to the power of Facebook manipulating voter behaviour during election time, One category in this section drew our intention: politics
Facebook offers targeting of US users based on their political views (conservative or liberal) and on a scale from likely to engage in politics, over moderate to very conservative or liberal. The clue on how Facebook can perform this kind of analysis and draw this kind of conclusions about each user can be found in a segment of our research Targeting based on the social connections and in patent – Inferring target clusters based on social connections (US 20140089400 A1) .
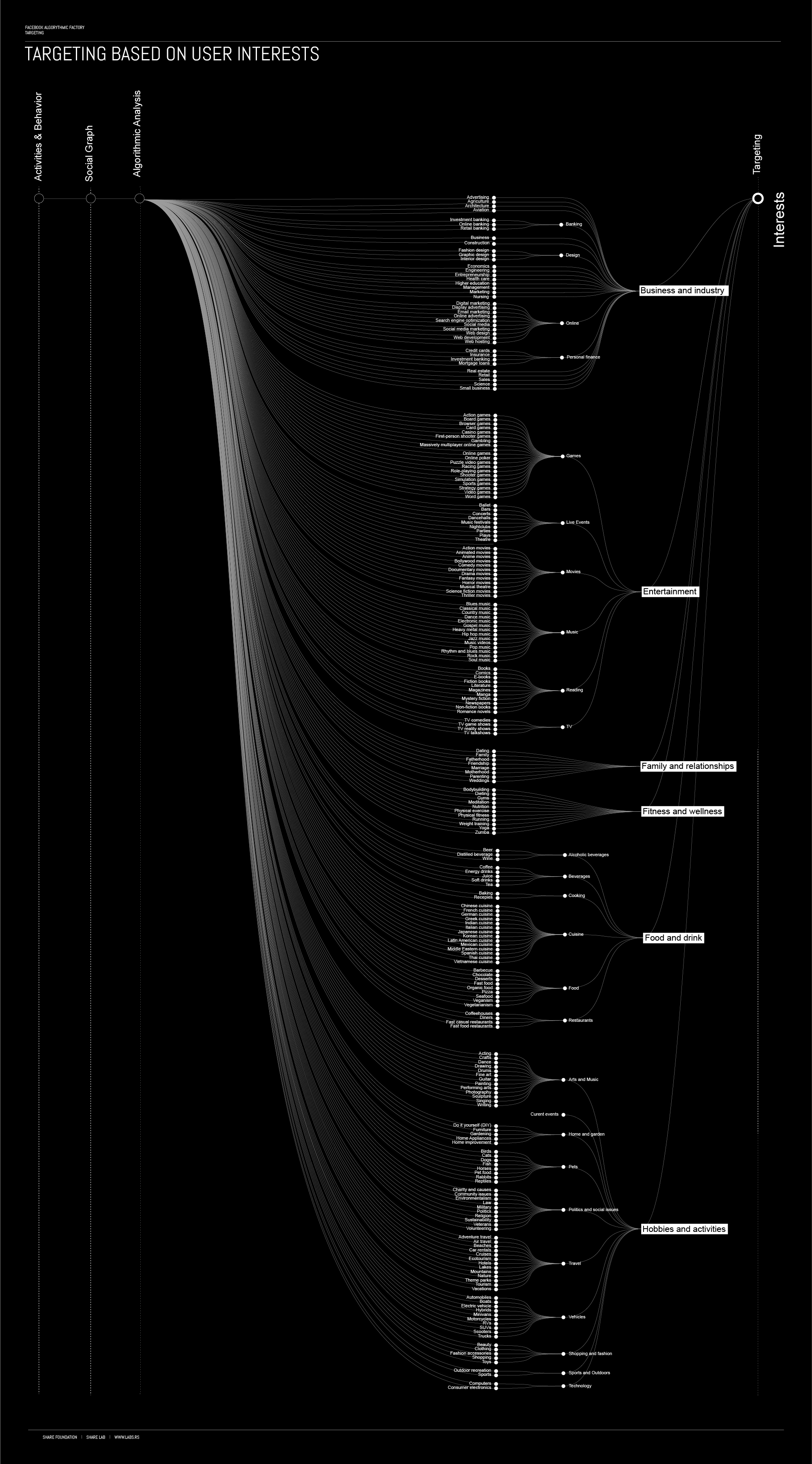
Targeting based on the user interest is by our opinion solely based on the process of Action data and Content analysis. As we explained before, during this process, keywords and topics are extracted from the user content and each content is basically tagged with associating keywords and topics. Interaction and actions of users related to content is then matched with the use of the fuzzy matching algorithms with the ads in different categories and subcategories.
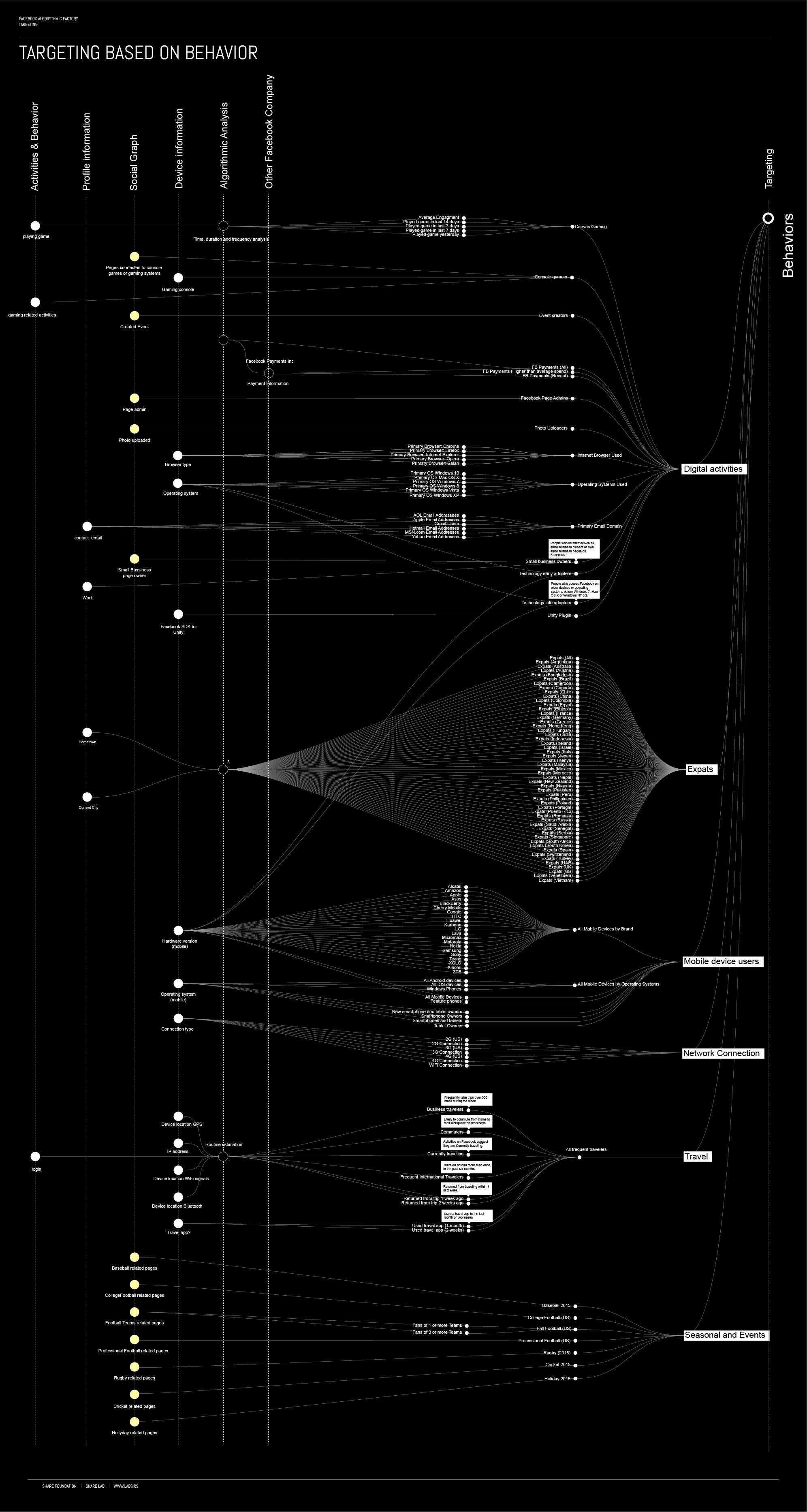
Targeting based on Behaviour is really diverse with different types data sources used for analysis.
The digital activities section is mostly based on the analysis of the digital footprint of your devices in combination with other forms of data from user actions and social graph. Facebook is tries to cluster users based on the devices or applications they use, frequency of content types that they create or time they spend playing games for example.
The most intriguing targeting option in this segment for us is – All frequent travelers section. Here Facebook offers targeting of Business and International travelers, Commuters, users who are currently traveling or users that returned from trip one or two weeks ago. It is clear that in order to perform this kind of targeting, Facebook needs to engage in location tracking of users and to analyse patterns of user behavior. Traces of how this is done can be found in patent WO 2014123982 A3 Routine estimation. This patent explain the analytic method of user geolocation data collected from devices over a period of time in hourly intervals. The algorithm analyses the repetition, or the user being at the same location at a certain hour on a certain day of the week. The algorithm then clusters these geolocations and labels them by a place. The algorithm can determine where the user lives, where they work, are they commuters or currently traveling abroad.
Another interesting segment is related to the analysis of financial transactions. In the previously explained patents: Inferring household income for users of a social networking system (US 8583471 B1) and Comparing Financial Transactions Of A Social Networking System User To Financial Transactions Of Other Users (US 20140222636 A1) we can find out how Facebook clusters users into particular income bracket. This is done through analysis of the information the user provides, i.e. Current and past work positions, current and past education institutions they have attended, life events, family relations and marriage status, user’s behaviour, websites they visit, purchases they make online. The algorithm uses different techniques including image analysis to recognise brands the user wears on photos they upload, how often they use brand names in posts and searches etc.
Outro : Cartography of Facebook Empire
Cartography, has been an integral part of the human history as an essential tool for humans, to help them define, explain, and navigate their way through the world. Most of the ancient maps, from the perspective of the GPS and satellite imagery enhanced present look like inaccurate and naive representation of the world, but they are the technological, scientific and artistic state of the art of their time. They are a clear representation of will and necessity to understand the world around us.
The Fra Mauro map, from around year 1450 by the Italian cartographer Fra Mauro. Source : Wikipedia
{kind=link}
Our capacity to map the Facebook Empire is similar to the effort of the ancient cartographers that travelled, observed and measured distances without any sophisticated tools and technologies whatsoever. In the same manner we like to think that the map of the Facebook algorithmic Empire we presented here is similar in precision to some ancient maps of the world. But, this can be a really optimistic idea. As opposed to geographical data, that change quite slowly, the shapes of the Facebook Empire change on daily basis. New algorithms and categories are being introduced, the system is tuned regularly, new components are being added. And all of this inside of the black box.
The patents that we examined and are publicly available are from different times and the methods explained in them are probably already replaced with new ones. To make the situation even worse, the patents become publicly available two years after they have been submitted. And two years in the world of the algorithms is like centuries. This is just a small portion of the problems around the idea of the algorithmic transparency.
For 36 minutes, from 2:32 pm until 3:08 pm on May 6th, 2010, the trillion-dollar stock market crashed (a crash known as Flash Crash), which was one of the most turbulent event in the history of financial markets.Caused by black-box trading, combined with high-frequency trading, resulted in the loss and recovery of billions of dollars in a matter of minutes and seconds. Regulatory bodies and the academic community investigated this few minutes long event for years in order to understand what happened in just a few seconds of this algorithmic madness. This brings us to the question of our capacity to independently audit algorithmic processes and black boxes that shape our world.
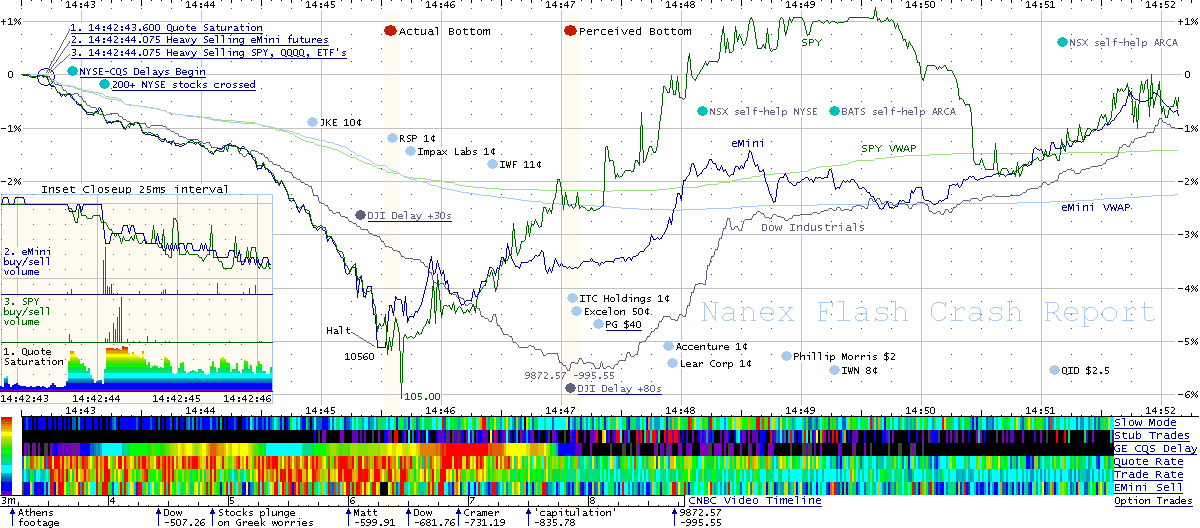 Source : Nanex Flash Crash Summary Report
Source : Nanex Flash Crash Summary Report
It is not so unreasonable to believe that even inside Facebook, there is no one who really has a full map of all the algorithmic processes that are happening at this very moment. Some of those algorithms are products of the brilliant minds and expertise of the most educated experts in the field that money can buy and it is hard to believe that any independent body will ever be able to oversight those algorithms in reasonable time and budget.
On the other hand, any kind of insight, any kind of map that can even superficially draw the shape of those complex processes can be considered a significant step into better understanding the algorithmic world around us. We see the outputs of this investigation as an advocacy and educational tool that can maybe spot some potential problems and lead to future, more exact investigations.
SHARE LAB 2016
VLADAN JOLER – RESEARCH, TEXT, DATA COLLECTING AND VISUALIZATION
ANDREJ PETROVSKI – RESEARCH, TEXT AND PROOFREADING
CONTRIBUTORS : KRISTIAN LUKIC AND JAN KRASNI