This is the second story in our investigation trilogy titled Facebook Algorithmic Factory, created with the intention to map and visualise a complex and invisible exploitation process hidden behind a black box of the World’s largest social network.
The three stories are exploring four main segments of the process:
Data collection – Immaterial Labour and Data harvesting
Storage and Algorithmic processing – Human Data Banks and Algorithmic Labour
Targeting – Quantified lives on discount
The following map is one of the final results of our investigation, but it can also be used as a guide through our stories, and practically help the reader to remain in the right direction and not to get lost in the complex maze of the Facebook Algorithmic Factory.
In his famous ”Postscript on the Societies of Control” Deleuze envisions a form of power that is no longer based on the production of individuals but on the modulation of dividuals. Individuals are deconstructed into numeric footprints, or dividuals,that are administered through “data banks” .
 17th century engraving of the pons asinorum in logic
17th century engraving of the pons asinorum in logic
Research tools and methodology : how data is stored and what kind of algorithms are inside is the hardest part to investigate. Luckily we found a source of knowledge that gave us some kind of insight into those mysterious algorithmic processes: database of all publicly available Facebook patents. We found around 8000 different patents registered by Facebook. Based on them we created possible interpretation of what happens within the black box. Another lead and source of information for us was Facebook Graph API, primary way for third party developers to get data in and out of Facebook’s platform.
Storing Data
Before we explore different ways how Facebook stores and analyses our data, it is important to understand the concept of social graph, a meta structure connecting all data into one structure.
Social Graph : One Graph to Rule Them All
The story of the Social Graph is the story of domination and ambition to rule the World of Metadata by interconnecting every piece of information within and outside of the Facebook Empire into one single graph. “It’s the reason Facebook works.” Said Mark Zuckenberg in 2007 attributing the power of Facebook to the Social graph.
A Social Graph is how Facebook represents all its data, and it’s basically about two things : Objects, also known as nodes and Connections that describe the links between these nodes also known as Edges
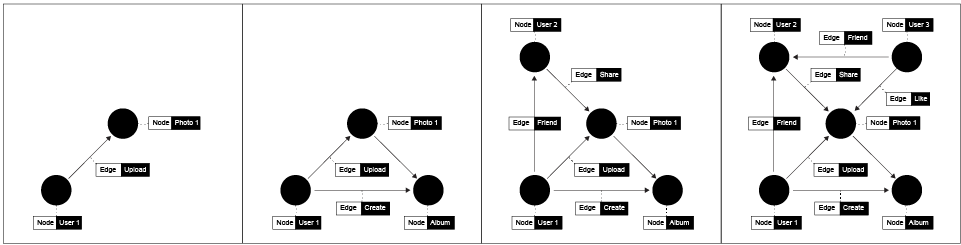
Every user, place, photo, group, event, everything created on or uploaded to Facebook is a unique object in the Facebook database with its own ID. For example, when you like some picture on Facebook, a connection <like> is created between the two objects, you <userID> and photo <photoID>. This photo can have many other connections, i.e. other users that liked the same photo, location associated with that photo or users that are tagged on that photo.
According to the Facebook API, there are the different types of nodes that exist within the Facebook social graph:
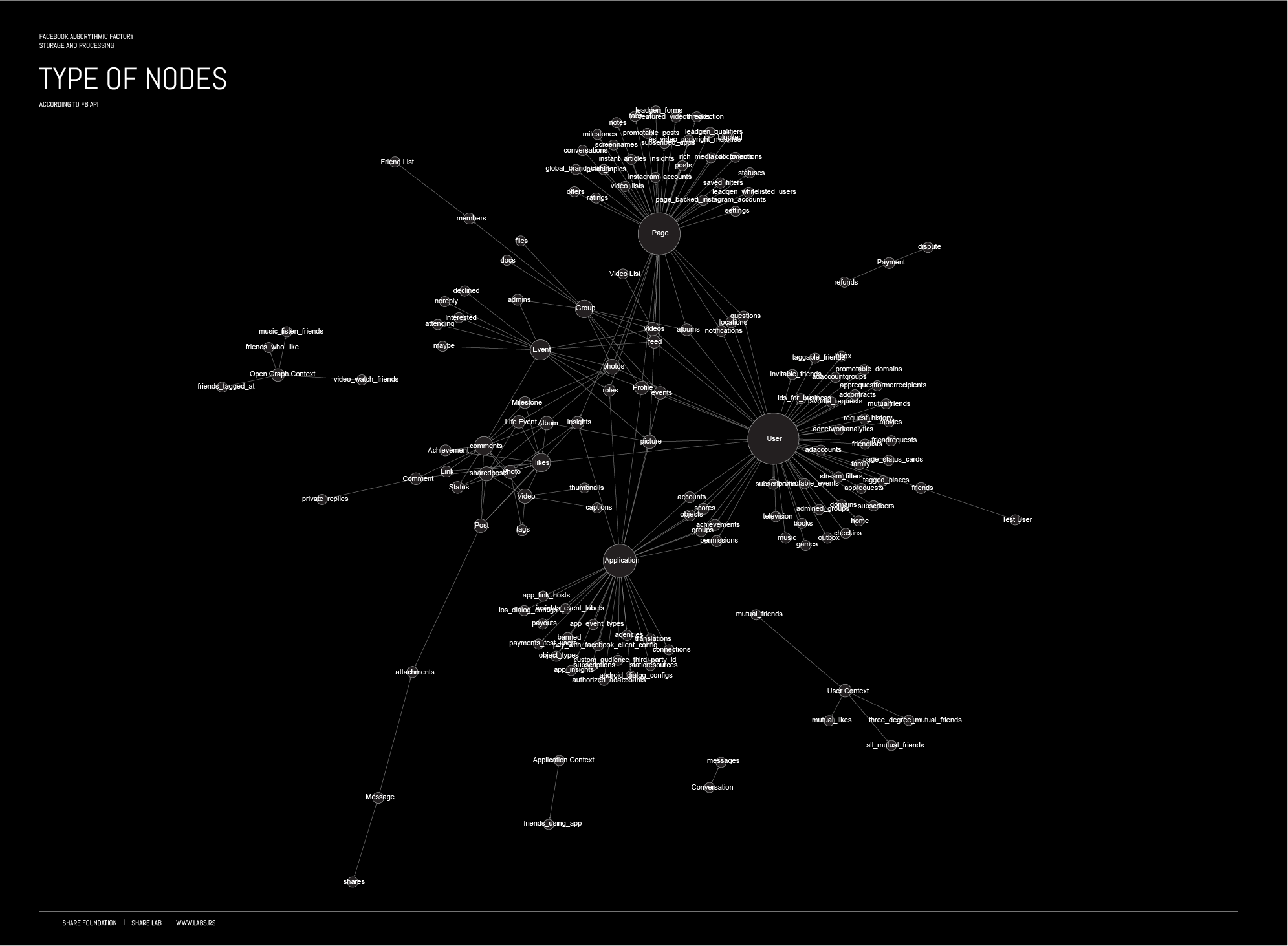
By using a social graph, Facebook is able to relate different users that have liked the same photo or relate people that are tagged on the photo with the location attributed to the photo.
the Facebook universe is a vast social graph made of billions of objects, interconnected by different kind of links.
Feeding the Social Graph
According to dozens of Facebook patents there are 3 different stores, databases that feed the Social Graph, and store all the data, metadata and content we create.
Action store maintaining information describing users’ actions.
Content Store – stores objects representing various types of content.
Edge store – stores the information describing connections between users and other objects
Content Store and Edge Store together are basically a database, structural resource for main meta structure, Social Graph connecting all objects and connections into one structure.
All our actions on Facebook are recorded by Action and Content Loggers that feed the Action and Content stores with new data, constantly expanding the data bank about us, owned by Facebook and potentially shared with many.
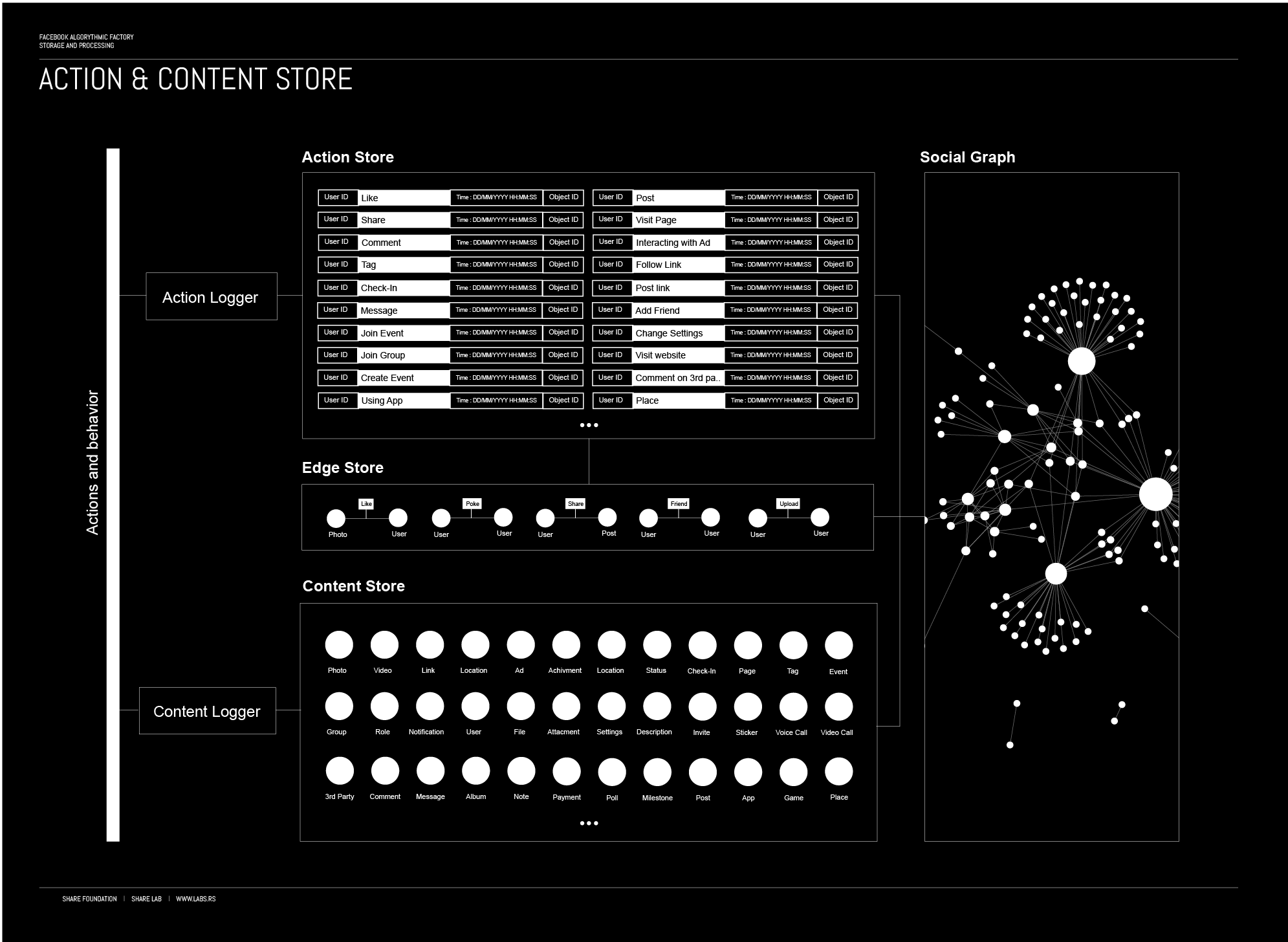
Action Store
Every click, like, share and basically whatever you do on Facebook is collected by an action logger and stored in the Action Store. The action store maintains information describing actions by users, as well as actions performed on third party websites that communicate information to the Facebook. Users may interact with various objects, as we explained before, maintained by Facebook, and these interactions are stored in the action store.
Examples of actions or interactions include: commenting on posts, sharing links, tagging objects, and checking-in to physical locations, commenting on a photo album, transmitting messages to another user, joining an event, joining a group, becoming a fan of a brand page, creating an event, authorizing an application, using an application, interacting with an advertisement, and engaging in a transaction.
Content Store
The content store stores objects representing various types of content such as page post, a status update, a photo, a video, a link, a shared content item, a gaming application achievement, a check-in event at a local business, a brand page, or any other type of content. Objects may be created by users or in some cases received from third-party applications (other websites or apps).
Edge Store
The edge store stores the information describing the connections between users and other objects. Some edges may be defined by users, allowing users to specify their relationships with other users. Other edges are generated when users interact with objects, such as expressing interest in a page, sharing a link with other users, and commenting on posts made by others. The edge store also stores additional information, such as affinity scores for objects, interests, and other information generated by the algorithmic processing that we will cover after.
Profile Store
As we already mentioned, our action data is collected and stored in the action, content and edge stores. On the other hand the information that we are share about ourselves in the profile information section are stored in Profile Store.

Each user is associated with a user profile, which is stored in the user profile store. A user profile includes declarative information about the user that were explicitly shared by the user and may also include profile information inferred by other means of data collection and analysis performed by Facebook. A user profile may include one or more direct characteristics that uniquely identify a user associated with the user profile such as e-mail address or a phone number. Those information can be used to identify user outside of the Facebook domain, indicates that the user profile and the additional user profile are associated with the same user.This allows Facebook to track users and merge information from other sources. Combined with Facebook’s “real-name system” that is dictating how people register their accounts and configure their user profiles, they can more or less accurately connect your user profile with your real identity. “Facebook is a community where people use their real identities. We require everyone to provide their real names, so you always know who you’re connecting with”
Those structures are buildings of the Facebook Factory, architecture where resource materials, data that is extracted from our behaviour is stored and prepared for the algorithmic workers to deal with. In next chapter we will explore the anatomy of some of the most interesting Facebook workers – algorithms that are transforming behavioural data into a final product.
Processing of data : Anatomy, tasks and responsibilities of an Algorithmic Labourer
Understanding how algorithms process vast amount of data and what is it exactly they do is of great importance for understanding the forms of possible exploitation of our personal data and mechanisms of manipulation on a large scale influencing billions of people every day.
One of our main goals in this research was to try to have an independent insight into those processes and we tried to come up with different methods for measurements or potential methodologies for independent audit of algorithms from the outside, but we faced a lot of difficulties. Nevertheless, even though we didn’t manage to create a methodology based on actual data, our research of Facebook patents gave us an insight into some of the most important processes.
What is an algorithm? Although for the purpose of storytelling it would be much more appealing to attribute algorithms with some superpowers, in most cases, we speak about some really amazing piece of code that applies some advanced statistical or analytical methods. The definition of an algorithm is: A procedure for solving a mathematical problem in a finite number of steps that frequently involves repetition of an operation; broadly: a step-by-step procedure for solving a problem or accomplishing some end especially by a computer.
 Euclid – Detail from the painting “The School of Athens” by the Italian Renaissance artist Raphael created between 1509 and 1511
Euclid – Detail from the painting “The School of Athens” by the Italian Renaissance artist Raphael created between 1509 and 1511
Action data analysis
As it was explained before, each and every activity on Facebook is being stored in the so – called Action store. That means that the action store is a huge, structured dataset of user activities, making it a quite convenient choice for a targeting mechanism.
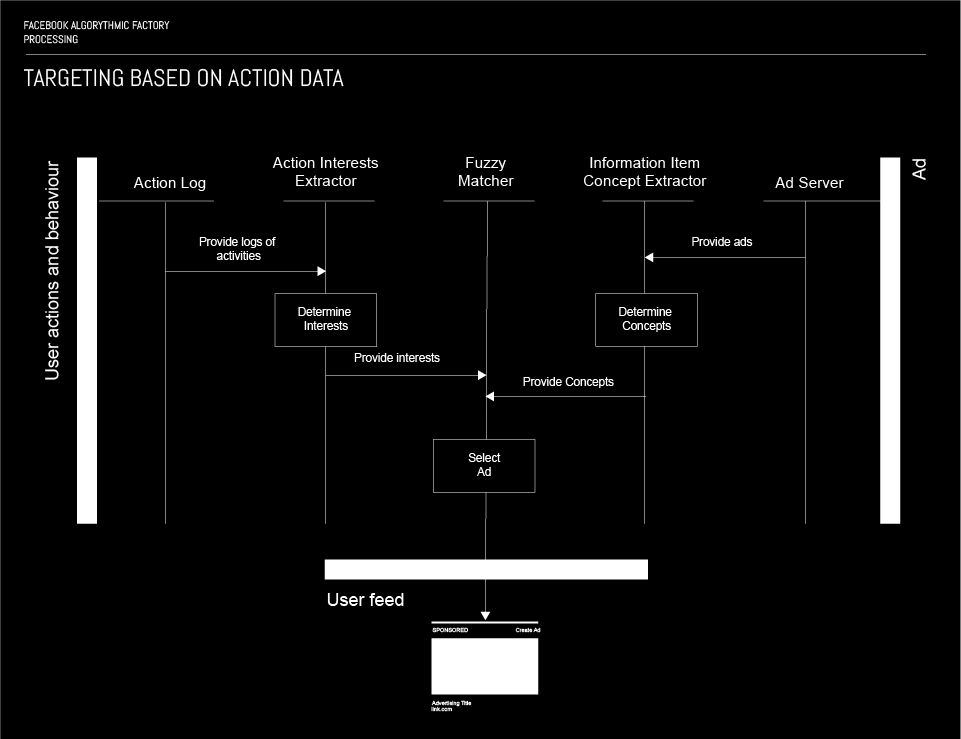
A Fuzzy matching algorithm is used as a principal mechanism for targeting based on data from the action store. Two parallel processes take place in order to generate the input for the fuzzy matcher. First, the activities logs are obtained from the Action log, by Action Interest Extractor. Once these logs are loaded in the Action Interest Extractor, the list of interests of the specific user is determined based solely on data from the Action log, i.e. his activities (clicks, likes, comments, shares, etc…). Then, the list of interest is forwarded to the Fuzzy matcher, as a query.
The second process is the process of selecting the adequate ad for the user that is being targeted by the Fuzzy matcher. The first step in this process is the Ad server providing ads to the Information Item Concept Extractor. Once a set of ads is loaded by the Information Item Concept Extractor, they are analysed and each ad has its concept determined, i.e. each ad is being assigned an attribute representing its concept.
Finally the Fuzzy matching algorithm performs a search, using the interests as a query; as a result selects an ad that makes the best match to the query, which is then being served to the targeted user.
Content analysis
In the previous couple of paragraphs, the mechanism of targeting users by using data from the Action store was explained. Apart from that data, data from the Content store are also being used for targeting users. Needless to say that in this case the targeting is based on contents users publish on Facebook in several different ways.
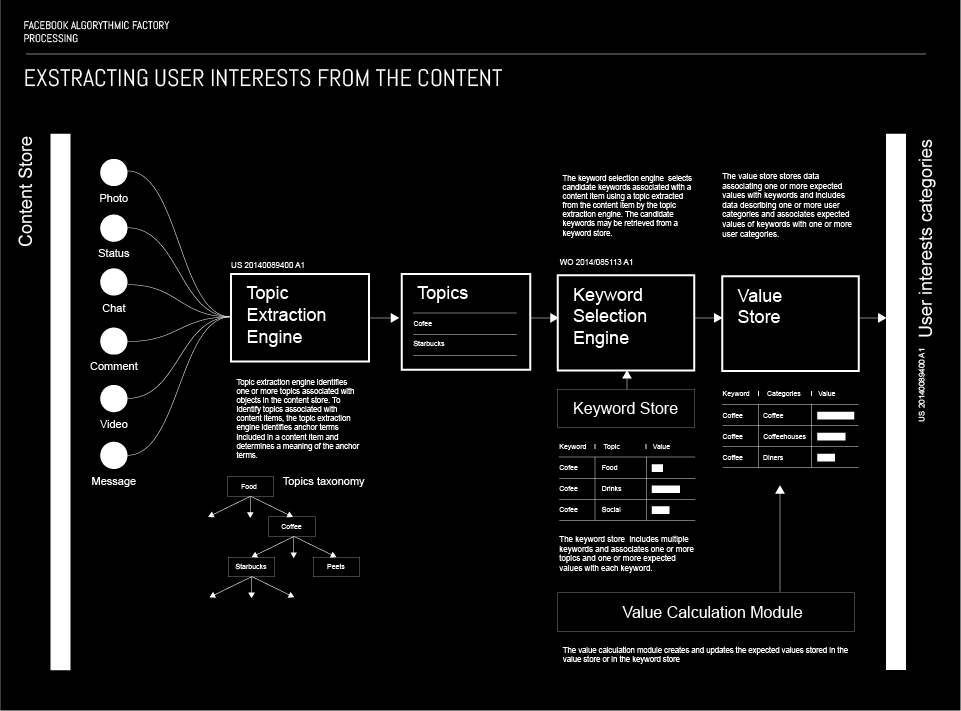
There are two relevant aspect of targeting based on content. The first one are the topics, and the second one are the keywords. When a user posts some sort of content to Facebook, there is a Topic extraction engine that identifies one or more topic associated with the content. In order to associate the topics with the content, the extraction engine analyses it and identifies anchor terms included in the content and determines the meaning thereof.
More about this processUsing the extracted topic, an algorithm defines a list of keywords and associates them one or more expected values. The algorithm uses information about the user to determine the values associated to the candidate keywords on the list. The assigned values are used for ranking the candidate keywords, with the highest ranking being chosen as one the most precisely defines the content.
When choosing what content, i.e. ads will be served to the user in the future, the algorithm uses the links created between the user and the keywords from the content.
An important input for content based targeting also comes from the Action store, and it’s related to negative signals to ad targeting. This is in fact a set of content that the user might have a negative sentiment towards, and is used to label ads that the users would not like to see. When Facebook determines, based on the user’s actions that they dislike particular object (content), it determines the topic of the object and associates negative sentiment to them. The association between negative sentiments and topics is used to decrease the likelihood that an ad matching the said topic will be served to the user.
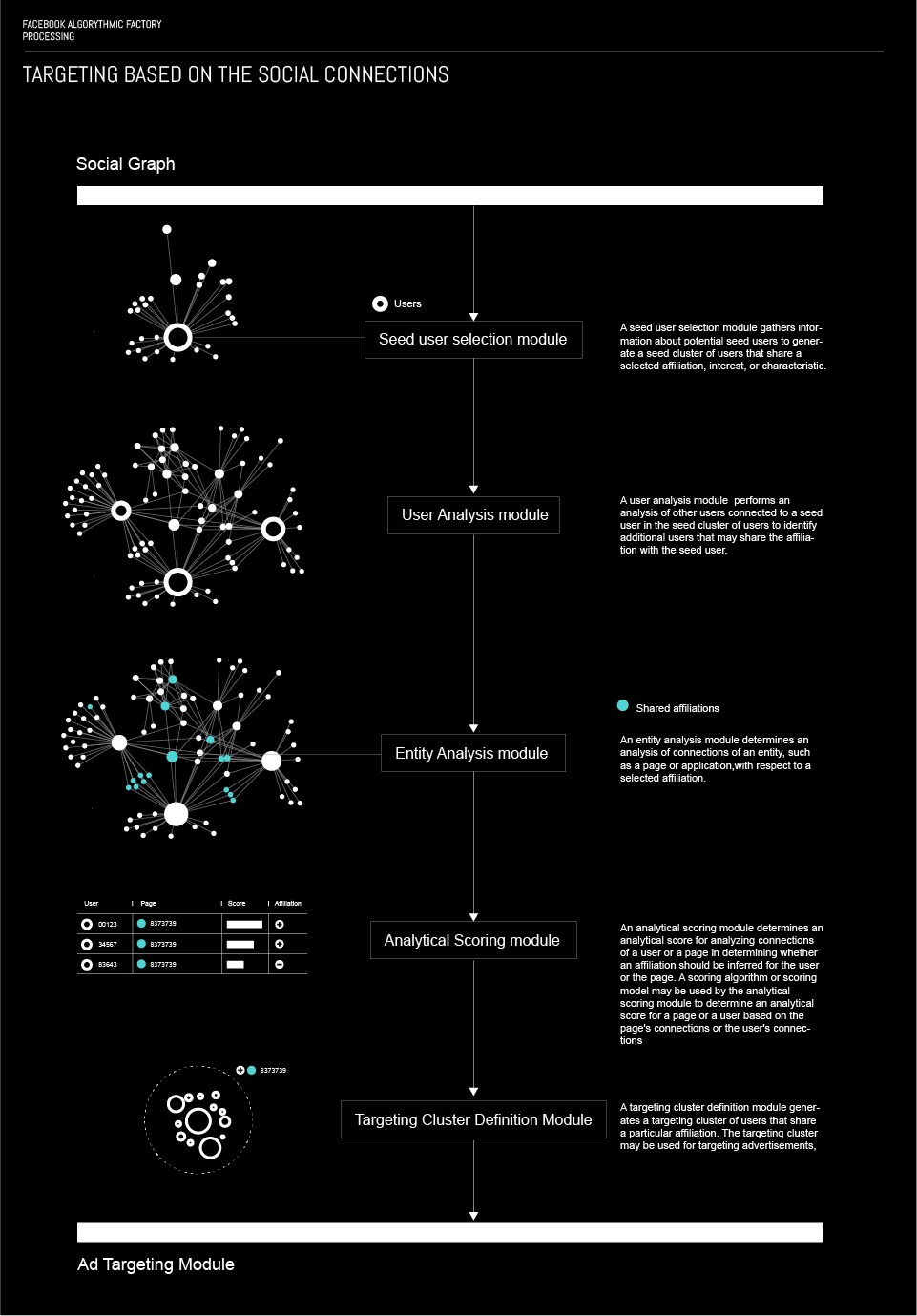
Important data for precise targeting is gathered by forming logical structures of users. Facebook, groups users who share a particular attribute into a structure called seed cluster. Once a seed cluster is created, a set of other users or objects that the user is related to is retrieved. Within these sets, an algorithm determines whether the users in the set share the same attribute as the primary user. The process of determination is based on explicit declaration of the secondary user, analysis of their connections and uses a random walk algorithm. The results are used to decide if the secondary user can also be associated to the cluster. As a result, a targeting cluster is established, and can be used for targeting users and showing them specific ads.
More about this processThe credibility of these clusters is tested by measuring click-through rates of users in the cluster for a particular ad or measuring negative feedback of users in the cluster. In addition to this, users can be put in a cluster based on their interactions with pages, applications etc.
The process of forming groups and subgroups, uses several different modules. First of all, the seed user selection module, which gathers information on potential seed (primary) users and creates a seed cluster of users who share a particular affiliation, interest, or characteristic. In the first stage the algorithm selects users that have explicitly stated these attributes on their profiles (like a page or the likes). However, activities, such as likes, comments, check – ins etc. related to the user can be used for clustering.
A second module is used to make subgroup based on the members of the group (users already in the cluster), by exploring their activities and attributes and checking whether they could form a part of the group. The process of data gathering for these secondary users is similar to the one used on seed users.
The entity analysis module is used to determine attributes of users based on their interactions with pages or applications. For instance if somebody supports a certain political party, the algorithm presumes that they would be interested in a certain types of cars, because most of the users that use a facebook application that shows the nearest selling points for said cars, support the said political party. What this module does is it groups people based on what objects they interact with and what type of users most often interact with such objects.
Some attributes of the user can be determined by evaluating their connections to other users. This is done by the analytical scoring module. This module determines particular attributes of the user by scoring their connections to other people. For instance, if a user has a few weak connections to other users that like white wine and stronger links to users that like red wine, this module would based on the strength on the connections (probably based on mutual interactions, check-ins, tags etc) will consider the primary user as one that likes red wine.
Once certain attributes are determined by the four aforementioned modules, a targeting cluster definition module generates a cluster of users sharing the same attributes. The clusters are used for serving specific types of ads, but also for specific targeting of content that the user is likely to enjoy seing. This way, besides generating revenue, Facebook, also controls the information flow to the user, based on preferences, that a set of algorithms has established. In a way, that could be considered censorship.
The process of forming groups and subgroups, using the aforementioned modules, as a complete flow has several steps. First of all users are structured into subgroups based on a similar attribute; then a centroid (a central user) of the group is identified, and through them, the characteristic of the entire group are identified. All the users in the subgroups are then ranked by the similarity of their attributes, to the ones of the central user i.e. the subgroup. Finally the subgroup is labeled as a whole, compact unit; for example, people who like red wine and Harry Potter.
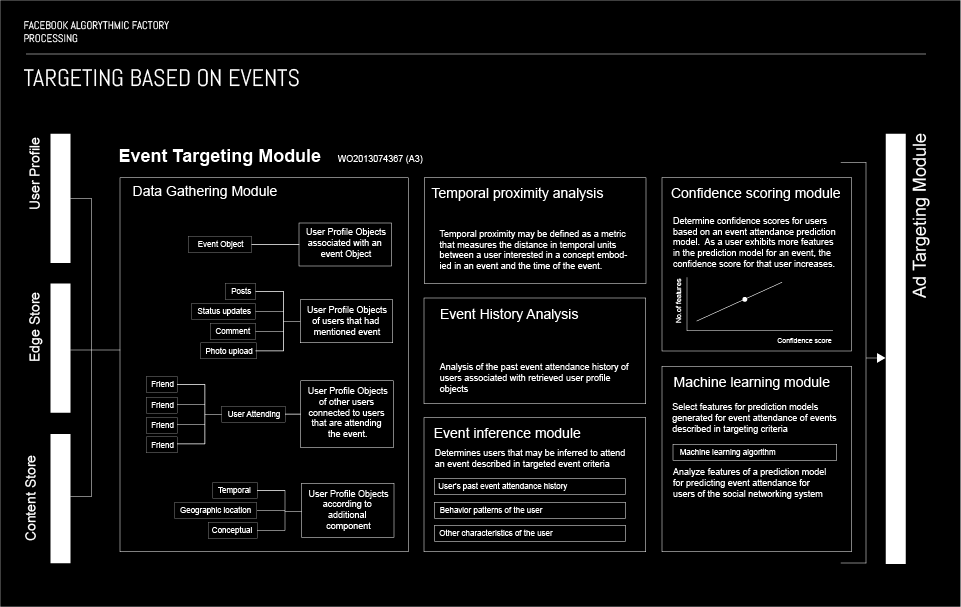
TARGETING USERS BASED ON EVENTS
This algorithm performs event targeting based on several different criteria. The first and most simple criterion that could indicate an association of a user with an event is the RSVP option on the events created on Facebook. However, since users can RSVP yes, but not attend an event, the algorithm can calculate whether they will really attend the event based on their previous attendance score, the number of their friends attending and the general event history. Additionally the algorithm uses other inputs, such as a check-in at the event venue, uploading a photo of the tickets for the event, record of purchasing tickets on an external website or tagging the event in a post. Event targeting is used on events on all scales from small, private events to global events.
More: PATENT WO2013074367 (A2)
Targeting objects to users based on search results in an online system
This algorithm makes use of the query users input into the search box on Facebook. The purpose of this algorithm is to serve the user with ads that correspond to their search query. As the use inputs the query in the search box, results matching the query are compiled, while the algorithm tries to recognise a structured nodes in the query and in the results. Then. it retrieves ads that correspond to the recognised structured node and at the same time retrieves information about the user. After matching the ads to the user’s information, i.e. attributes, it determines which ads should be shown with the results of the query. This practically happens as the user types in the query, so it is quite hard to perceive it as something so well structured.
More: Patent WO 2014099558 A2
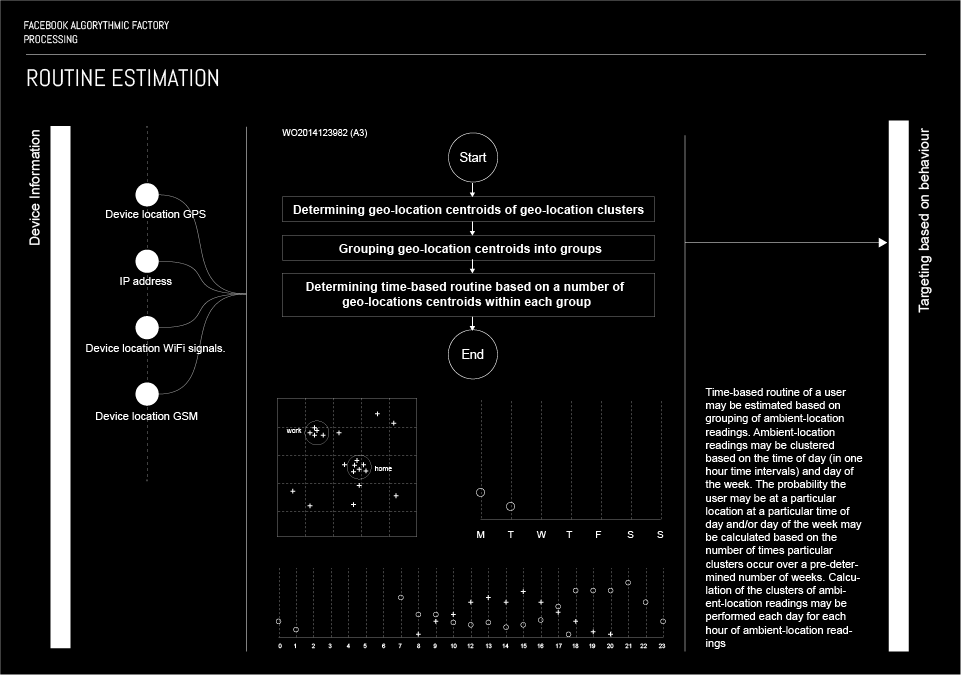
Routine estimation
This algorithm determines the routines of a user by analysing the geolocation of a user over a period of time in hourly intervals. The algorithm uses data about user’s geolocation provided by mobile devices, such as smartphones, tablets or laptops, or rather sensors installed in these devices, i.e. GPS sensor, gyroscope or a compass; the Facebook app installed on the device gathers the necessary data and feeds them to the algorithm. Next, the algorithm analyses the repetition, or the user being at the same location at a certain hour on a certain day of the week. The algorithm then clusters these geolocation centroids; afterwards the clusters are labeled by a place that corresponds to the geolocation centroids in the cluster. In that manner, the algorithm can determine where the user lives, where they work, if they go to the farmer’s market on a saturday morning, do they go to the gym and how frequently etc.
More : Patent : WO 2014123982 A3
Inferring household income for users
This algorithm maps a user into a particular income bracket. This is done through analysis of the information the user provides, i.e. Current and past work positions, current and past education institution they have attended, life events, family relations and marriage status. However, since users have the ability to provide false information to Facebook, this algorithm further analyses user’s behaviour, websites they visit, purchases they make online etc. The algorithm uses different techniques to map the user in a particular bracket, including image analysis to recognise brands the user wears on photos they upload, how often they use brand names in posts and searches etc. These information is then used to enable advertisers to easier target their appropriate target group by income. Also, the machine learning algorithm has the ability to detect when users have given faulty information or have forgotten to update their information, such as change of workplace, moving to another city marital status and the likes.
More: Patent US 8583471 B1
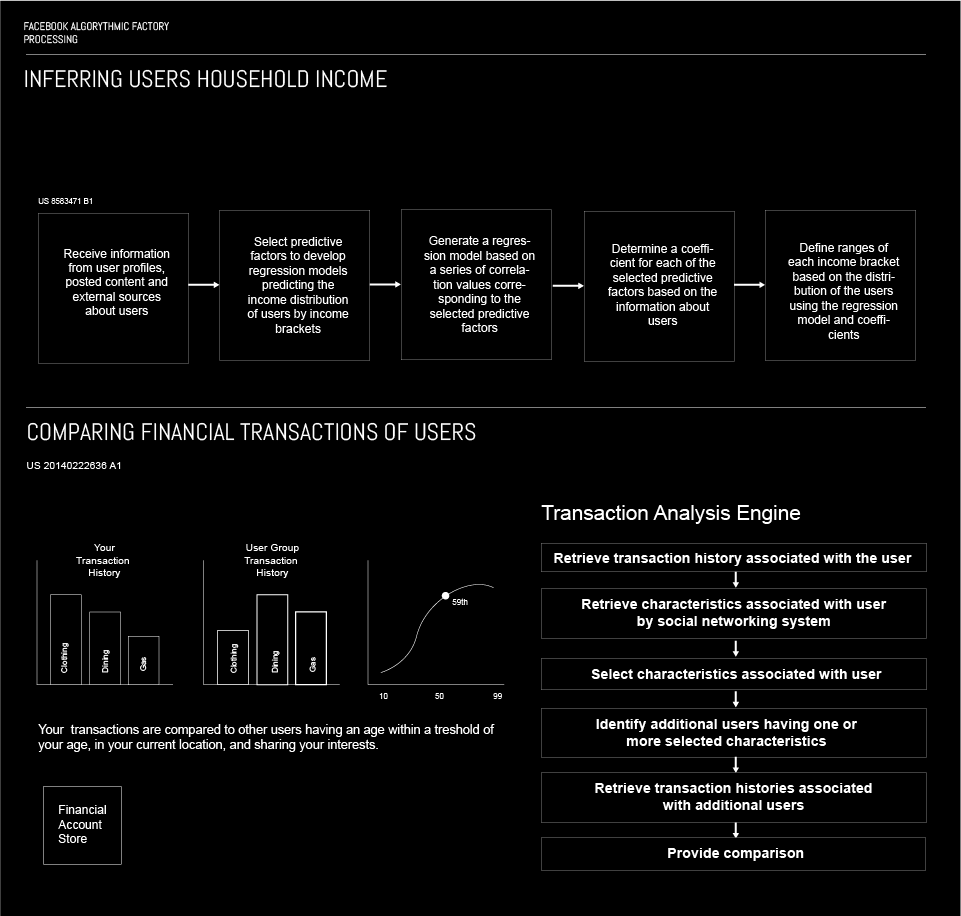
Comparing Financial Transactions Of Users
What this algorithm does is comparing the buying habits of a user compared to a group of users the user can be associated with by sharing similar attributes, such as age, location, education level, work position etc. The algorithms analyses search queries, visits to external websites and other types of transactions within Facebook and on third – party websites. Using this data, the algorithm can provide the user with analysis of former transactions, but can also predict future spendings, for example it can predict how much would a user spend on travel by comparing his previous transactions to other users that share similar interests, have the same age and live in the same city as the primary user.
More: Patent US 20140222636 A1
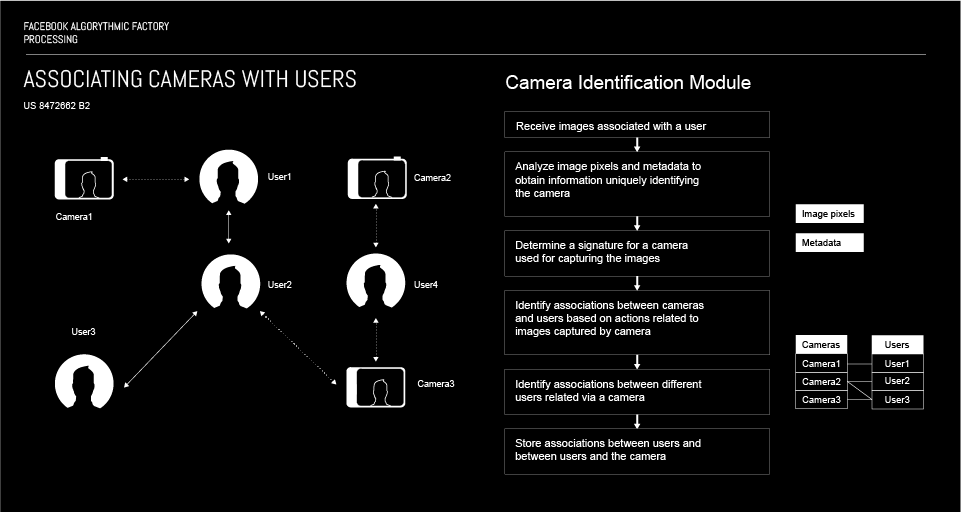
Associating cameras with users of a social networking system
This algorithm associates Facebook users based on pictures and/or videos taken using the same camera, i.e. device. When photos or videos are uploaded on Facebook, the UI, camera signature is red by the algorithm and it serves as a connection point for users uploading photos or videos taken using the same device, i.e. camera. This can be used for detecting fake accounts, a user having multiple accounts; but also for the purpose of a social graph, i.e. recommending friends, prioritising news feed, etc.
More: Patent US 8472662 B2
There are some, in our opinion, interesting and relevant algorithms that are used in the process of quantification and monetisation of our everyday life. The featured algorithms are just few examples of probably hundreds and hundreds of different algorithms that try to understand every our action and post, classify us into nano-sub categories and predict our future behaviour. We encourage the readers of this text to explore by themselves the available patents and continue this research in order to understand this phenomenon.
In the third and final part of this story, Targeting – Quantified lives on discount, we will explore the form of the final product of the Facebook Algorithmic Factory and discuss issues and problems related to mapping the Facebook Empire.
SHARE LAB 2016
VLADAN JOLER – RESEARCH, TEXT, DATA COLLECTING AND VISUALIZATION
ANDREJ PETROVSKI – RESEARCH, TEXT AND PROOFREADING
CONTRIBUTORS : KRISTIAN LUKIC AND JAN KRASNI