

In this article, we will try to map some elements of Facebook’s human fabric, the social structure and the power relations within the company.
We will investigate and reflect upon the phenomenon of Facebook in terms of the social networks of its employees. We will also consider the social relations between the members of Facebook’s management board and other spheres of society. This article is a contribution to the contemporary critique of the strong ties between political establishments and global business, i.e. that of the issue of the revolving door.[2] In short, we will deal with the phenomenon of digital capitalism.
In order to grasp the employment structure of Facebook, we have used public LinkedIn profiles of 1000 people indicating Facebook as their employer as well as the biographies of the entire management of Facebook. By mapping their social background, education, status, and present position in the hierarchy of the company, we gained insights into the various social connections of the “Facebook government” as a whole. These insights can be used to explain some of the actions of the company and the network – related actors and the [evolution of the] business model and can be helpful to try and predict future developments.
Knowledge Labour Aristocracy
We want to learn more about the personalities, their embeddedness into classes and their networks within and outside the closed society of the Facebook corporation; we want to find out how these classes are structured, to know more about the people these classes consist of, how they move or migrate around the world. We are also interested in understanding of roles of all the persons around Mark Zuckerberg who rule or serve this corporation. While asking ourselves about the people who build the Facebook pyramid, we have in mind the notion of class determinism and the idea that the classes reproduce themselves and create the environment in which its members will be able to function optimally. Bourdieu’s notions of social space, habitus, the cultural, educational/informational, and social capital (Bourdieu 1982, 1997) were present in our reflections before and during the research. The mentioned terms introduce Marx’ idea of capital accumulation which shouldn’t be forgotten when thinking about the Facebook collective or any other representative of digital capitalism. Figure 1: Dinner in the salle des spectacles at Versailles – Eugene Louis Lami
Figure 1: Dinner in the salle des spectacles at Versailles – Eugene Louis Lami
Source : Wikigallery.org
We can think about almost any class of the Facebook employees as a perfect example of highly paid knowledge labour aristocracy.[7] This model is the opposite example to other forms of labour hidden behind the surface of IT industry, “such as slave-labour extracting minerals, the labour of militarily controlled and highly exploited hardware assemblers, precarious digital service workers, imperialistically exploited knowledge workers in developing countries, workers conducting the industrial recycling and management of e-waste, or highly hazardous informal physical e-waste labour” (Fuchs 2016: 61). On the top of this pyramid of knowledge labour, we see the small circle of ‘silicon sultans’, network of individuals who control or have significant influence on the biggest companies in the field, sit in their boards or own parts of their shares.
 Figure 2: Robber Barons
Figure 2: Robber Barons
Source : Robber Baron or Captain of Industry….What does that mean? (video)
The original accumulation of the capital in the United States shows some intriguing similarities with the oligarchy from the Silicon Valley.[8] The second half of the 19th century was marked by the creation of the infrastructure (railroads) for the American single market, and by the transition to industrial society, bringing innovative products to the doorsteps. The American ‘robber barons’ of the 19th century amassed huge wealth by squeezing out the competition, much like today’s ‘silicon sultans’. An illustrative comparison will show us: “Rockefeller once controlled 80% of the world’s supply of oil; today Google has 90% of the search market in Europe and 67% in the United States while Facebook has 42% of the social media market share in US only” (Economist 2014). Similarities between these two groups of infrastructure pioneers lead to a warning conclusion: the characters spearheading the transformation of an industrial age into an information society on a global scale “stand accused of being greedy business folk who suborn politicians, employ sweatshop labour, stiff other shareholders and, especially, monopolise markets” (Economist 2014). Once regarded as ‘inventive mould-breakers’, silicon sultans now digress into solving mankind’s problems, from ageing to space travel, grounding their entitlement in the data industry the world became dependant on.

On Top of the Pyramid: the Board and the Management
In order to visualise the connections of Facebook’s (FB) management,[9] i.e. its board of directors and advisors, and two executive levels, we used publicly available information provided by the Official Board and Crunchbase websites.[10] For every person on these lists we analysed educational and professional background as presented in his or her official biography. It should be borne in mind that all of these people are in the public eye and that their biographies are not secret. Thus, all of the given information is available to everyone who wishes to find it, and our use of it is not a result of any illegal or covert activity.
The following network should help us deepen the understanding of the connections within the board itself and the ties between the Facebook and the industry, the ties of Facebook and the government, and the ties of Facebook with civic organisations (such as e.g. think-tanks).

Figure 3: Facebook Management Graph
In the centre of the graph is Mark Zuckerberg, surrounded by the board members. As shown in the upper left corner, the yellow rectangle marks board members, the black rectangle marks the first level of executives, and the white rectangle the second level of executives. The networks surrounding these actors connect the educational institution from which they obtained their degree, their position within Facebook, and/or ties to a previous position in a respective organisation. The organisations can be of different types as mentioned above: company; investment fund or venture capital; university and/or research institute; foundations and non-profit organisations; government institutions; and non-governmental institutions such as think-tanks. Each of the actors is connected with several organisations in different ways.
Here are few examples of how you can read this map:
Marc Andreessen: Nexus of power – In the lower right corner, we find Marc Andreessen, one of the board members in the inner circle of Zuckerberg’s closest colleagues in Facebook. As we can see, he has been educated at the University of Illinois, which is a part of biography which doesn’t connect him with any other of his FB-colleagues. He is, however, also partner in one of the most influential venture capital firms in the Silicon Valley “Andreessen Horowitz”.[11] Through this company Andreessen is connected with very important companies such as Foursquare, Groupon, Skype, Twitter, eBay, AOL and GitHub. He is an example of a very powerful person who has a rather integrative function in the market since his business ties connect major players in the field.[12] This kind of interconnectedness raises the question if the companies of Silicon Valley are in the risk of being in cartels and trusts or if they are already beyond that. In other words, this and similar connections underpin the idea that Facebook has a successful concept because it attracts influential actors. They also do not remove suspicion that the company would not be as successful were it not for these actors. If we decide to follow one of his connections, as depicted on the graph above, we can see that Andreessen has interest in communications and financial services: through his venture capital firm he was an investor in Skype, and he is still the board member in eBay. The previous vice president of both companies was Dan Neary who is presently second level executive in Facebook and works for/with Sheryl Sandberg on the Asia Pacific market.
Peter Thiel: Agencies and Analytics – Peter Thiel (lower left corner), one of the most influential people in Silicon Valley and the member of the FB management, is also an early-stage investor in the LinkedIn network (where the retrieved data about the FB-employees come from). He is co-founder of world known PayPal, Clarium Capital (a global macro hedge fund), Founders Fund (a venture capital firm), Valar Ventures, Mithril Capital, and has served as a partner in Y Combinator, making him one of the most powerful figure in the venture capital sphere, extending his influence over hundreds if not thousands startup companies. One of companies Thiel founded is drawing special attention – Palantir Technologies, an analytical software company. A document leaked to TechCrunch revealed that Palantir’s clients as of 2013 included at least twelve U.S. governmental bodies, including the CIA, DHS, NSA, FBI, CDC, the Marine Corps, the Air Force, Special Operations Command, West Point among others.[13] This company was originally funded from In-Q-Tel, the Central Intelligence Agency’s not-for-profit venture capital arm, and was used by different government agencies. Even though the some of his close colleagues in Silicon Valley do not share enthusiasm about it, Thiel became advisor of U.S. President Donald Trump and his bridge to the tech community. In addition to Erskine Bowles (who will be mentioned further below), this is a second important connection of Facebook management board to politics and political parties.
Sheryl Sandberg: Government, Financial Sector and Corporations – Sheryl Sandberg’s position at Facebook is Chief Operating Officer and the director. She controls operations related to small businesses, advertising and global operations, global marketing, games sales, etc. In the “life before Facebook”, her studies at the Harvard Business School brought her to work as an assistant for her professor and to subsequently become the Chief of Staff at U.S. Secretary of the Treasury.[14]Except for being in the series of foundations and non-profit organisations that gather influential women from the business and government, she is/was also board member in the think-tanks such as Center for Global Development or Brookings Institute which (among other tasks) deals with the defence policy of the U.S. Less important but an interesting fact is that she was the board member of Starbucks Coffee This shows in a rather amusing way, that all the mentioned actors are by no means limiting their business interests to the digital or online economy, but are, on the contrary, interested into other sources of income as well.The example of Sheryl Sandberg clearly shows strong ties on the personal level between state institutions and private capital. She stands for a civil servant who became very influential in the business sector.
Ties to Politics and Parties
The member of the board Erskine Bowles, (upper left corner) from the inner circle around Mark Zuckerberg, has been also Chief of Staff in the White House, and is the co-chair at the National Commission of Fiscal Responsibility and Reform, a governmental body that he himself helped to establish in 2010.[15] His ties to the financial industry through his work experience in Morgan Stanley,[16] and in the technological industry through General Motors[17] show the kind of systemic support that Facebook can rely on through the members of its board. Erskine Bowles stands for the connection of the financial, technological and IT industry with the politics and with the Democratic Party. Even if it is not so easy to talk about the protectionism in the classic meaning of the word, these connections do show the common interest of the actors within the political administration with those of the private business.
This kind of political engagement in the context of mentioned lucrative businesses is problematic from the standpoint of European public and political tradition. From the perspective of civil rights and privacy policy, the strong institutional connections between the governmental bodies, secret services and social networks, i.e., communication infrastructure can only be seen critically. Mentioned examples show how elites merge with political establishment to concentrate power. We remind readers, however, that this phenomenon is generally not seen as something wrong in the U.S. since all these people are publically talking about these achievements as something highly positive. At the same time, similar ties are to be found in other branches of industry and in other countries. By no means advocating it, we think that the global success of a company like Facebook would not be possible without these kinds of capacities.
Google’s kiss to Facebook
As we will see further in this paper, among the transferred professionals working for Facebook, the number of former employees from Google is the highest. Regarding the managing class of Facebook, we can see that the Google node (in the centre, above Zuckerberg) on the graph is also important since it connects several important actors. Shant Oknayan from UAE is responsible for the Middle East and North Africa (MENA) region in the E-commerce, Retail, Online Services and Media. He, however, came from the similar post at Google. Tom Stocky, director of Search department, used to be Director of Product Management at Google. David Fischer and previously mentioned Sheryl Sandberg both used to be vice presidents of Global Online Sales and Operations at Google. A similar situation emerges when it comes to the Microsoft or the Apple nod at this map. According to the graph, in case of the higher management, most of them already had experience of working for some of the top companies in the field. This fact supports the idea that the higher strata of new knowledge labour aristocracy is already defined and is only rarely pulled up from the lower strata.
***
Management ties and education
The following graph is based on the same set of data but visualised in form of the alluvial diagram. It can help us to get a better insight into the educational background of Facebook’s top management and board members.

Figure 4: Facebook Management. Ties and Education
It is interesting to notice that people from the managing class of Facebook are not only from the Ivy League universities. They do come mostly from the best ranked U.S. or the best ranked world universities – most of them have been studying at Stanford, Harvard, or Columbia University. However, this is not the criterion for any of them to be at the position they are now. In so far, it could be possible to talk about social mobility concerning the lack of connection between the rise in the company and the educational background. One example is Jan Koum who could be seen as an outsider with his background at San Jose State University, but shows that his experience with Yahoo and Ernest&Young fits the profile of an average Facebook board member – and is benevolent in his own project WhatsApp.[18]

Within the Pyramid: The Adventurous Journey of the Lower Knowledge Strata into Labour Aristocracy
As mentioned above, in order to learn more about the Facebook employees, we were using publicly accessible data from the LinkedIn network. We used modification of Littlefork[19] which scraped the profiles of 1000 people stating in their professional activities that they are or have been working for Facebook. We believe these data are useful only to a certain extent since there is no way of checking their complete accuracy. The total number of Facebook employees in 2015 according to 10-K form was 12,691[20]. We think that for the ethical reasons and social responsibility Facebook should represent in its employee and managerial structure the gender, culture and race of its global market and not only the U.S. American one. The results of our research show that Facebook represents (significant parts of) U.S. political, social, and economic elites instead.
 Figure 5 : Educational and Professional Development of Facebook Employees – PDF Version
Figure 5 : Educational and Professional Development of Facebook Employees – PDF Version
Figure 5 shows the professional and educational background of Facebook employees (it does not say anything about the managers and executives). It should be read from the top to the bottom as follows: the country of study on top is the country where the person employed studied, whereas the following category shows the university stated in their LinkedIn biographies. Below that we can see the job position before joining Facebook. The highest number of employees started to work for Facebook right after their studies and majority of them originates from the U.S.A. In other words, only a very small percentage of FB-employees, who began to work for the company immediately after their studies, came from educational institutions outside the U.S.A.
***
The following category shows the professional origin of those employees who came to Facebook as experienced professionals. Most of these people came from the top 20 internet companies in the world; the second-largest group comes with a very similar professional background. However, they did not come from the top 20 companies working online. The third largest group came from the top 20 IT companies.[21] Facebook itself is known for employing in its Research and Development (R&D) department a large number of people with academic backgrounds. According to our data, this percentage is not very high, as can be seen in Figure 5 below. The sectors of consulting, business, finances, and investment together with sourcing and human resources consist of heterogeneous professional backgrounds.
***
After joining Facebook, some employees get relocated. Most of them stay within or move to the U.S.A. However, the number of people working in the U.S.A or moving there is by far larger than the number of Facebook employees anywhere else in the world. The next country with a significant number of Facebook employees is the United Kingdom, followed by India and Ireland. Approximately the same number of employees are located in India, Ireland, and Singapore. The next countries on the list are Japan, Romania, Brazil, and the United Arab Emirates, but these cannot compare in terms of numbers of employees with the places mentioned before. When we talk about urban centres, the largest number of people working for Facebook is located in the San Francisco area. The second-largest city of importance for Facebook is, however, not in the U.S.A. but in the U.K. – London. We see the reason for this large difference in the numbers in the inconsistency and unreliability of the data for the fine-grained personal information such as place of living. One of the facts that confirms problems with the data set is that among the urban centres we also find countries such as Singapore or Ireland. For the same reason, we believe some other cities in the U.S.A. are therefore not represented on this list.
***
Concerning the field of professional activities, the vast majority of the people stated on their accounts that they are working with computer software. The other groups further below are called Internet, Information technology and services, Staffing and Recruiting, Marketing and Advertising. These are problematic and could be regrouped to build larger fields since it seems that at least some of them share the same activity. On the bottom of this graph we see the job list as stated on the LinkedIn profiles. The largest group belongs as expected to Software Engineers. The second largest group goes to Recruiting (HR). Finally, a number of smaller professions are stated (such as Engineering Manager, Research Scientist, Product Manager etc.) which also can be regrouped in larger fields or be to some extent added to the largest group. We don’t doubt the validity of the data for the largest groups and find it plausible that the recruitment takes such an important place for the company. We can conclude from these proportions that the selection process it one of the most important activities in the company’s work (facilitating internal value), and that the engineering field is the most valued one for the company (facilitating products). These relations should be kept in mind while reading the following chapter.
***
Positions at Facebook: Education Profiles and Distribution
The following network and table figures are based on the same database (1000 Linkedin accounts), however, combined with the data about the board members and top management. They show us the institutional and educational background of specific positions and of the members of the management.

Figure 6: Facebook Labour Network Graph – PDF Version
The kinds of nodes are defined as follows (see the upper left corner): white circles mark positions at the company, yellow circles mark board member and the first level executive, and the universities are marked by rectangles.
In the middle of the graph we see the largest accumulation of people and institutions around the job title of software engineer which is not insightful because so many actors are related to it. However, in the upper left corner we can see that engineering managers usually come from seven universities. Colin Stretch, the leading engineering manager in Facebook, studied at one of these universities: Dartmouth College. On the other hand, it should not be a surprise that Harvard attracts the largest number of executives: on the right side of the graph we can see many of them: Elliot Schrage, Diego Dzodan, Lori Goler, Sheryl Sandberg, Carolyn Everson, and Dan Rose. It is especially interesting that the key profession connected here is that of business marketing editor. Mark Zuckerberg, famous as a Harvard dropout, is not directly connected to this school, but is still in its circle. In the upper right corner, an interesting connection appears between the several executive members from different fields such as product engineering and executive recruitment in digital marketing. It is interesting that production engineers are always somehow connected with Massachusetts Institute of Technology (M.I.T.) regardless of the university they originate from. The same goes for the people working in community operations. The executive members concentrated around M.I.T. are Rebecca van Dyck (production engineer), Shant Oknayan, and Tom Stocky. The largest number of board members are concentrated in the lower central part of the map. They are all connected to Stanford University where most of them studied. The job titles related to this institution are People analytics and Payroll associates.
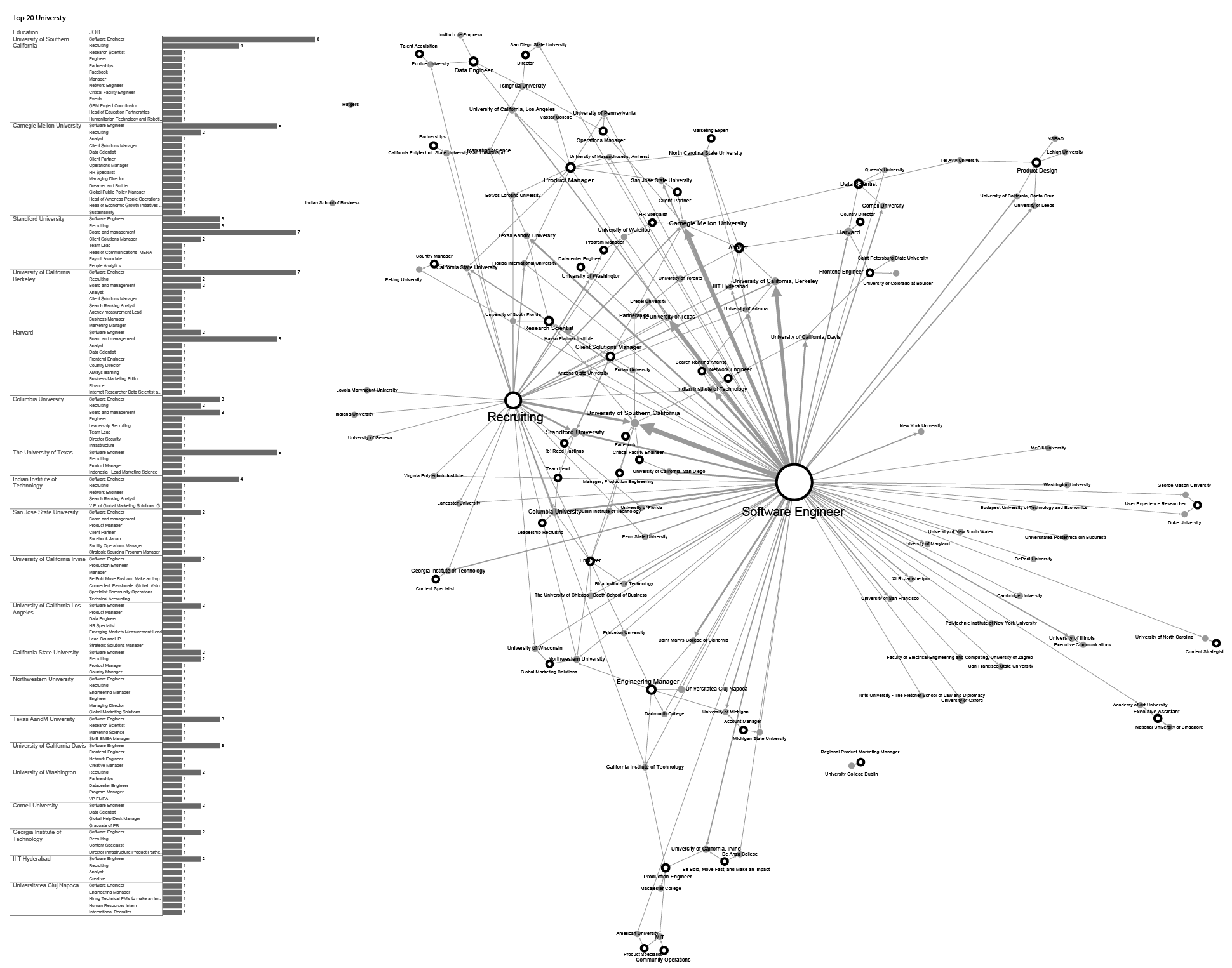
Figure 7: University Background and Position at Facebook
This network and the figure 7 show us even more precisely which job titles and professions are tied to which university. In the table on the left-hand side you can see universities ranked according to how many Facebook employees studied there.
***
Ties and Cuffs
Figure 8 shows previous ties of the board members with significant number of employees who come from the specific company to Facebook. We were interested if we can confirm the tendency that board members bring their colleagues to the new job or at least support this kind of relocation among the companies they themselves are/were connected with.
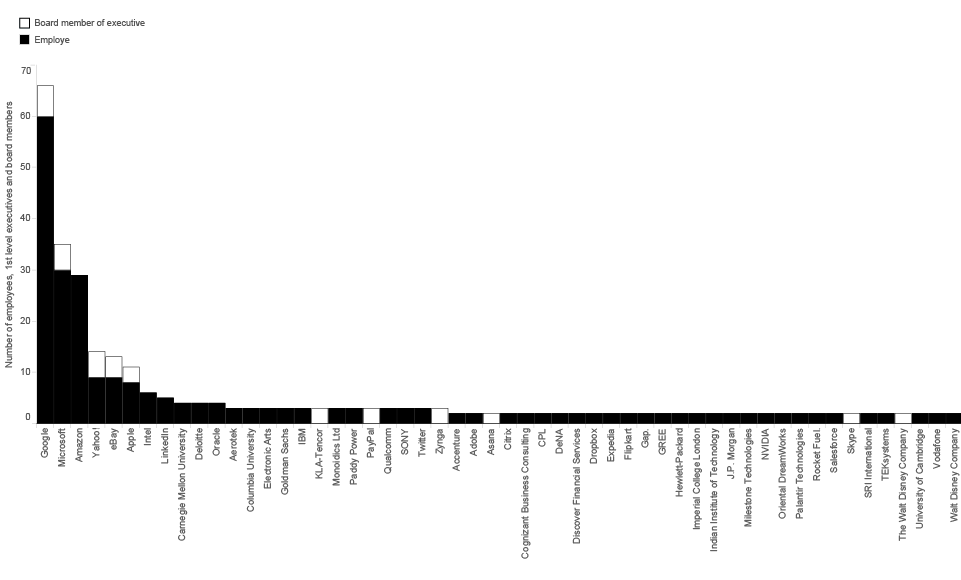 Figure 8: Previous ties
Figure 8: Previous ties
As expected, the largest number of professionals comes from the companies such as Google, Microsoft, Amazon, Yahoo, eBay, and Apple. However, there is significant difference between the ties of Google and Facebook, and all the others. We believe that in spite of all the legal measures against such actions, this graph shows cooperation in competition. Based on the percentage of people circulating among these companies and the positions and professional background of the same employees, this graph makes visible to which extent knowledge and technology exchange takes place between these entities. Such systemic ties could also be seen as building of cartel or some kind of trust which destroys the “industry ecosystem” by the means of controlled monopoly. It is hard to believe in real competition, if the competing companies share the knowledge base, experts and boards. Of course, the public data we are operating with can only indicate the possibility of the problem, they do not serve as the evidence of any kind.
***
Migration of labour: Agglomerations vs. Deserts
We already described some of the relocation processes among the FB employees around the world. On our Migration of Labour chart, it is possible to see the relation between the current country (horizontal, above) and the country of study (vertical, on the left side) of the 1000 evaluated profiles from the LinkedIn.
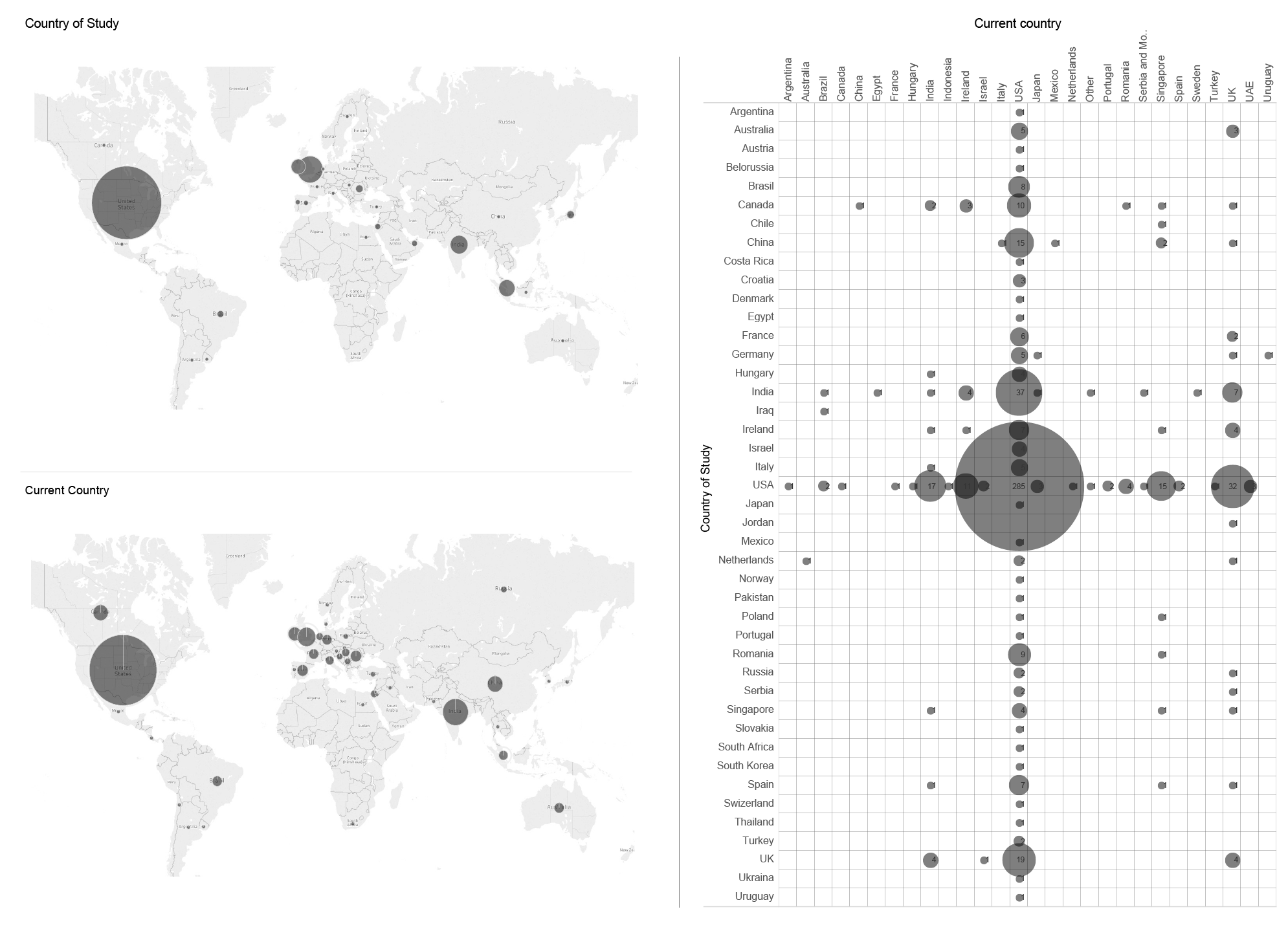
Figure 9: Migration of Labour
By comparing these two axes we can see the country where the person was studying and where he or she went after the studies. Most of the employees are attached to the U.S., as visible in the central crossing point marked by the grey bubble. Also, the largest number of people went to the U.S. after their studies, as visible at the same dot. Most people who left the U.S. after studies, went to work for Facebook in the U.K., India or Singapore. All these places are known for their FB-offices. This chart shows that Facebook as an employer mostly recruits people from U.S. universities. This means that in spite of acting globally, this company does not see the need to represent the structure of its users around the world. As seen before, the dominance of the U.S.-based education is obvious also in the managing board. We can speculate if the HR and Recruiting officers have a policy (which does not have to be an official one or in written form) of focusing on the people from the U.S. education system.
The same data can be visualized in a form of the maps, where current location and country of study of the employees is represented by the dark grey colour.
The Human Fabric of the Web
Sketching out the the social structure of a large company such as Facebook is a task which is important not only in order to understand the impact of such a global internet phenomenon as the social network on the society, local and global economy, and civil freedoms, but also to better understand how the development of high-end technology and communication infrastructures intertwine with the accumulation of capital and political power. Even though the world is at the point of postglobal development (a point where global is already reached and the new local is what the market needs), the deep embeddedness of the company in the economic, political and social elite/establishment of one society/country is what makes the company strong enough to act globally – and not, as is often thought, through the cooperation of the elites around the world. The comparison with the pyramid or the Leviathan comes handy because of the many social tiers and faces that build up to the one which stands in the centre and is known to everyone. At the same time, as our investigation shows, the real fabric of the web consists of the personal social networks of specific people in the higher strata of the company. If anything other than its profit, this is what keeps the whole structure together and safe from any change in the political establishment.
 Illustration by Abraham Bosse for the book “Leviathan” writen by Thomas Hobbes (1668)
Illustration by Abraham Bosse for the book “Leviathan” writen by Thomas Hobbes (1668)
Specific ties which create the network are not hidden, even though the myth says that the invisible puppet master pulls the strings. As we can see, it is actually a relatively complex network of many knots with dynamics driven by the interests of specific actors. Companies of this size influence, organise, and determine the lives of elites, the global economy, the everyday life of “small people” or “average users” (as we can define the people today). It is important to describe precisely how and to which part of the network which actors are tied. Once we understand the deep intertwining of the large companies with politics, it is easier to recognise and articulate the support of those forces in the political arena which are pleading for the legal separation of these branches of society.
***
Credits:
Data analysis and data interpretation: Jan Krasni
Data organisation, analysis and visualisation: Vladan Joler
Data collection: Christo and Andrej Petrovski
Thanks to Fieke, Leil, Christo and Claudio from Tactical Tech and Oli, Andrej and Psyho from SHARE Lab for the week of collaborative data collection and investigation that lead to the data set used for this research. Thanks to Kate Maxwell for hints on language and sadistic comments, and Steven Surdiacourt for the help with formulations. Thanks to Jaspal Singh for the challenging comments and the final touch.
–
Share Lab & Tactical Tech
Made mostly in Berlin, Novi Sad and Belgrade in 2016 and 2017
***
Literature:
Bourdieu, Pierre (1982). Der Sozialraum und seine Transformationen. In: Die feinen Unterschiede – Kritik der gesellschaftlichen Urteilskraft. Frankfurt am Main.
Bourdieu, Pierre (1997): Zur Genese der Begriffe Habitus und Feld. In: Der Tote packt den Lebenden, Hamburg.
Fuchs, Christian. 2016. Critical Theory of Communication. London: University of Westminster Press. DOI: http://dx.doi.org/10.16997/book1.b. License: CC-BY-NC-ND 4.0
Krüger, Uwe (2013): Meinungsmacht. Der Einfluss von Eliten auf Leitmedien und Alpha-Journalisten – eine kritische Netzwerkanalyse. IPJ, 2016
Krüger, Uwe (2016): Mainstream. Warum wir den Medien nicht mehr trauen. C.H. Beck, München
Internet sources:
https://www.statista.com/statistics/273563/number-of-facebook-employees/, (15/9/2016)
https://www.statista.com/statistics/311836/facebook-employee-gender-department-global/, (15/9/2016)
https://www.statista.com/statistics/311847/facebook-employee-ethnicity-us/, (15/9/2016)
https://www.crunchbase.com/organization/facebook#/entity, (12/9/2016)
http://www.theofficialboard.com/org-chart/facebook, (20/9/2016)
https://exposingtheinvisible.org/resources/obtaining-evidence/revolving-door-google (10/6/2016)
https://googletransparencyproject.org/articles/googles-revolving-door-us. (15/10/2016)
http://www.economist.com/news/briefing/21637338-todays-tech-billionaires-have-lot-common-previous-generation-capitalist (15/10/2016)
https://www.crunchbase.com/organization/facebook#/entity (on 1/3/2017)
https://www.theofficialboard.com/org-chart/facebook (15/2/2017)
http://a16z.com/, https://en.wikipedia.org/wiki/Andreessen_Horowitz, (11/5/2016)
https://en.wikipedia.org/wiki/Palantir_Technologies, (11-9-2016)
https://techcrunch.com/2015/01/11/leaked-palantir-doc-reveals-uses-specific-functions-and-key-clients/, (3/5/2016)
https://en.wikipedia.org/wiki/United_States_Secretary_of_the_Treasury, (23/11/2016)
https://www.fiscalcommission.gov/, (12/5/2016)
https://en.wikipedia.org/wiki/National _Commission_on_Fiscal_Responsibility _and_Reform, (12/5/2016)
https://en.wikipedia.org/wiki/Morgan_Stanley, (14/5/2016)
https://www.morganstanley.com/,(14/5/2016)
https://en.wikipedia.org/wiki/General_Motors, (17/5/2016)
www.gm.com, (17/5/2016)
Tools:
Data collection – Littlefork (https://www.npmjs.com/~tacticaltech)
Data visualization – Gephi, Tableau, RawGraphs
Footnotes:
[1] The term Dispositif deals with the whole socio-technical network which we cannot always see, but are immersed into in the everyday life. It corresponds rather with the Agamben’s term apparatus than with the Foucault’s original term.
[2] This text is written in the moment of a “power vacuum” and the “regime change” between the Democratic and the Republican party in the United States. This means that the ties between the industry and the establishment are to be rearranged and that this text shows only the present state. Some new social networks between the actors we are analysing here and the political stakeholders will come to place in the near future. There is no doubt that the ties between the establishment and the infrastructures will go loose.
As for the revolving door issue topic, check the: https://googletransparencyproject.org/articles/googles-revolving-door-us and https://exposingtheinvisible.org/resources/obtaining-evidence/revolving-door-google (10/6/2016)
[3] http://www.lombardinetworks.net/
[4] http://www.theyrule.net/
[5] littlesis.org
[6] https://bureaudetudes.org/
[7] Fuchs, Christian. 2016. Critical Theory of Communication. Pp. 47–73. London: University of Westminster Press. DOI: http://dx.doi.org/10.16997/book1.b. License: CC-BY-NC-ND 4.0
[8] This paragraph is based and the quotes come from the Economist’s article from 2014: “Robber barons and silicon sultans”: http://www.economist.com/news/briefing/21637338-todays-tech-billionaires-have-lot-common-previous-generation-capitalist (15/10/2016). We will reference it as Economist 2014.
[9] It is important to state that in this article we did not investigate different shareholders of the Facebook company nor we considered the invisible labour in Facebook related companies in third countries (or in ‘third world countries’). This would take too much time and would go beyond the borders of the topic. However, we do plan to elaborate on this topic in one of our future articles in the Facebook Research series.
[10] https://www.crunchbase.com/organization/facebook#/entity (on 1/3/2017) and https://www.theofficialboard.com/org-chart/facebook (on 15/2/2017)
[11] http://a16z.com/, https://en.wikipedia.org/wiki/Andreessen_Horowitz, (11/5/2016)
[12] Having percentage of stocks does not mean one is also in command (of technology for example). However, Andreessen is usually either investor or the board member of the mentioned companies, which certainly gives him possibility to help his companies both with technology and insider knowledge and to get any kind of information from them. Competing and cooperation of those companies gets through this a new quality.
[13] https://techcrunch.com/2015/01/11/leaked-palantir-doc-reveals-uses-specific-functions-and-key-clients/, (3/5/2016)
[14] https://en.wikipedia.org/wiki/United_States_Secretary_of_the_Treasury, (23/11/2016)
[15] National Commission of Fiscal Responsibility: https://www.fiscalcommission.gov/, (12/5/2016) and https://en.wikipedia.org/wiki/National _Commission_on_Fiscal_Responsibility _and_Reform, (12/5/2016).
[16] Morgan Stanley: https://en.wikipedia.org/wiki/Morgan_Stanley, (14/5/2016), and https://www.morganstanley.com/,(14/5/2016).
[17] General Motors: https://en.wikipedia.org/wiki/General_Motors, (17/5/2016), and www.gm.com, (17/5/2016).
[18] It is clear that people like Koum are not on the board because of their education, but because of what they brought to Facebook – in this case it was the WhatsApp with all of its user data. But it is also clear that some (sets of) skills correspond with the rest of the community.
[19] https://www.npmjs.com/~tacticaltech (15/08/2016)
[20] https://www.sec.gov/Archives/edgar/data/1326801/000132680116000043/fb-12312015x10k.htm (16/09/2016), check also: UNITED STATES SECURITIES AND EXCHANGE COMMISSION Washington, D.C. 20549 FORM 10-K
[21] There are important differences in the field of work between internet and IT companies, and there is usually not too much significant overlap between their primary purposes. In order to understand this better, one may think about Yahoo and Microsoft and their official division of work.
]]>
The three stories are exploring four main segments of the process:
Data collection – Immaterial Labour and Data harvesting
Storage and Algorithmic processing – Human Data Banks and Algorithmic Labour
Targeting – Quantified lives on discount
The following map is one of the final results of our investigation, but it can also be used as a guide through our stories, and practically help the reader to remain in the right direction and not to get lost in the complex maze of the Facebook Algorithmic Factory.
With 1.6 billion active users in 2015, Facebook is heading towards fulfilling their mission to connect every person on this planet through their social network. Zuckerberg’s vision, which is becoming reality, most people on the planet are connected between each other through one application, the social networking app. According to its creator, Facebook was built to accomplish a social mission – to make the world more open and connected. To be fair, this social network has in fact made the lives of billions of people more open and transparent, and made segments thereof more exposed to the public.We are the witnesses of the time of transparency of the individual. At the same time, Facebook, the platform itself is far from being open and transparent. What happens within the invisible walls of this complex algorithmic machine mediating the communication of billions of people is kind of mystery, a black box .
There are many reasons why we should be interested in these black boxes mediating and recording our interaction, our deepest personal communications, our behaviour and activities. Within those invisible walls, in every moment algorithms are deciding which information will appear in our infosphere, how many and which of your friends will see your posts, what kind of content will become part of your reality and what will be censored or deleted.
On other hand, this black box has defined new forms of labour, exploitation and generation of enormous amount of wealth and power (17.93 billion dollars in 2015) for the owners of this invisible immaterial factory creating a deep economic gap between the ones who own and control the means of production and the users who often live below the poverty line.
Somewhere deep under the layers of algorithmic machines there can be hidden new forms of potential human rights violation, new forms of exploitation and mechanisms of manipulation on a large scale influencing billions of people each day.

Those are the raw resources exploited within Facebook Factory.
Where Surveillance economy meets immaterial labour
According to the Marxist theory, when creating a good, people operate on the subjects of labour, using the instruments of labour, to create a product 1. The means of production include two broad categories of objects: instruments of labour (tools, factories, infrastructure, etc.) and subjects of labour (natural resources and raw materials). For example, in an agrarian society the means of production are the soil and the shovel. In an industrial society they are the mines and the factories, and in the knowledge economy the offices and computers.

| Type of Society | Who is performing labour? | Objects of Labour | Instruments of Labour | Product |
|---|---|---|---|---|
| Agrarian society | Human workers | Soil, seeds | Shovel | Food |
| Industrial society | Human workers | Natural resources and raw materials | Mines, factories, machines, tools |
Goods, products |
| Information society | Human workers | Information, knowledge | Offices, computers | Business, educational, intellectual products and services |
| Algorithmic society | Algorithms | Digital content, digital footprint, metadata | Social networks, digital platforms, devices | Profiles, patterns, anomalies, predictions |
If we try to understand the production process and creation of products at the Facebook factory in this context, we come to conclusion that there is one important difference. The main raw materials in the process (data, content and metadata) are the objects of labour and they are created by humans, but the labour itself is performed by algorithms.
IN THE EARLY 2000S TIZIANA TERRANOVA 2 STATED THAT FREE LABOUR OF USERS IS THE SOURCE OF ECONOMIC VALUE IN THE DIGITAL ECONOMY. DIGITAL LABOUR OF USERS CAN BE ALSO DESCRIBED AS AFFECTIVE AND SOCIAL ACTIVITIES THAT ARE NOT TYPICALLY VIEWED AS WORK, SUCH AS FOR EXAMPLE UPDATING YOUR PROFILE ON A SOCIAL MEDIA WEBSITE, WRITING COMMENTS OR TAGGING PEOPLE ON PHOTOS .
So basically whatever we do on Facebook can be described as some form of free digital labour. According to Trebor Scholz and Laura Y. Liu, ”the instruments of digital labour are indeed everywhere; they are fast-changing and invisible. Without being recognised as labour, our location, input, and tracked mobility become assets that can be turned into economic value.”
Every one of over 1 billion Facebook users, digital workers, work averagely 20+ minutes per day on liking, commenting, and scrolling through status updates. That is more than 300.000.000 working hours of free digital labour per day.
We should be clear that the main products of the Facebook factory are not billions of texts,updates, uploaded photos or videos. As we will explore in our investigation they are just a resource, playground for algorithmic social network analysis, classification and algorithmic profiling. Looking from anthropocentric perspective we like to put our self and our labour into the main focus, but in this case, the main form of labour is done by the algorithms. Products of this immaterial factory are more than a billion different user profiles, categorised and ready for sale. Specifics of this system is that users that are being used as a raw material are constantly working on fine tuning of themselves as a target, feeding this system with more and more information about themselves. It is kind of perfect marriage between free immaterial labour and surveillance economy.
Inside Facebook algorithmic factory
In our first part of investigation we will try to put a light upon how our behaviour, actions and information collected, stored, analysed and finally transformed into the products.
Our approach in mapping this invisible system is to find all the inputs and outputs and then try to describe what kind of actions were performed in between.
Our methodology consists of using different investigation tools on the publicly accessible resources. Three main parts in this research concern the Facebook data collection, its storage and analysis, and the targeting types applied to the users:
| Investigation Tools | Resources |
|---|---|
| 1. Data Collection | |
| Facebook Data policy analysis | https://www.facebook.com/full_data_use_policy |
| Mapping all the input fields on the Facebook platform | https://www.facebook.com/ |
| Cookies and pixel technology analysis at the 3rd party websites | https://www.facebook.com/help/cookies/update https://labs.rs/en/invisible-infrastructures-online-trackers/ |
| Policy analysis of Facebook owned companies | https://www.facebook.com/help/111814505650678 |
| Research on Facebook Vendors, service providers and other partners. | https://facebookmarketingpartners.com/ |
| Facebook Ireland Ltd Report of Audit (2011) | http://www.europe-v-facebook.org/Facebook_Ireland_Audit_Report_Final.pdf |
| 2. Storage and data analysis | |
| Facebook Patent database research | https://www.google.rs/search?tbm=pts&hl=en&q=inassignee%3A%22Facebook%2C+Inc.%22+ |
| Facebook API | https://developers.facebook.com/docs/graph-api/reference/ |
| 3. Targeting | |
| Facebook Ad creation process | https://www.facebook.com/ads/manager/creation/ |
Data Collection : Extracting data from the biomass
Data harvesting, extraction of data from the biomass in the human fields is an essential operation, one of the foundations of the Facebook Empire.

Human fields from the Movie “matrix” (1999)
According to our investigation Facebook utilises different ways to extract data from our behaviour and activities within and outside of the Facebook domain that we can separate in following groups :
A.Within Facebook
Every like you make, every step you take, every photo you upload, every event you attend, is recorded and stored by Facebook, in their databases. We can separate two main categories of information collected within the Facebook domain. First there are all the interactions, created or uploaded content, pages visited and basically everything you do on Facebook – Activities and behaviour.

We could perceive the second group as rather voluntarily provided content – all the information you provided about yourself in the Profile information segment.
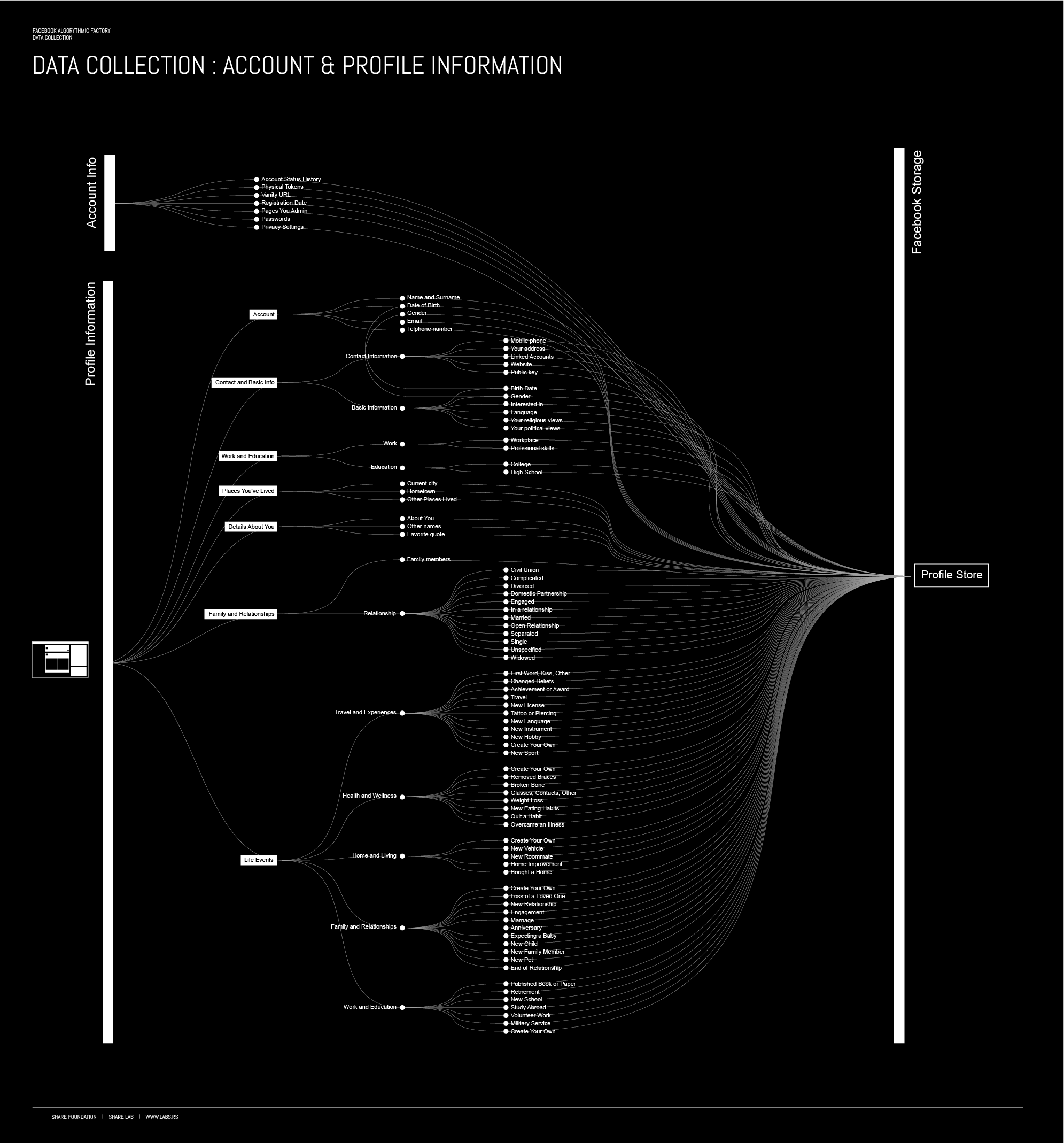
There is a significant difference between those two groups of information. Profile information are basically static information that are rarely updated and depend on the direct input you (are free to) give, on the other hand activities and behaviour inputs are dynamic and represents what you like, share, create and interact with in real time. Profile information can quite often contain misleading or faulty information.
B.Digital Footprint
Digital Footprint harvested from your devices is the second great resource of information Facebook has about. In this case we have two main categories as well: Information that can be gathered from your mobile devices and digital footprint that can be collected from laptop or desktop computers you use to access Facebook.
Information that can be gathered from laptop or desktop computers are not as diverse in comparison to information that can be gathered from mobile devices. However, they can still reveal a lot of information about you. Some of those information include your IP address, operating system, browser type and other information that can be used as a unique identifier and combined with information gathered through cookies and pixel technology reveal different behavioural patterns.
Cookies
Facebook is not gathering information just within Facebook domain, thousands of their invisible tentacles for data collection are reaching almost half of the world wide web. Our research on Online Trackers revealed that on the top 50 websites in Serbia that we use there are in 46% of the cases some of the Facebook cookies embed.

“Cookies are small pieces of text used to store information on web browsers. Cookies are used to store and receive identifiers and other information on computers, phones, and other devices. Other technologies, including data we store on your web browser or device, identifiers associated with your device, and other software, are used for similar purposes. We use cookies if you have a Facebook account, use the Facebook Services, including our website and apps (whether or not you are registered or logged in), or visit other websites and apps that use the Facebook Services (including the Like button or our advertising tools).”
Facebook Cookies Policy
According to the research we conducted on the 50 most frequently visited websites from Serbia there are in average 7 different 3rd party cookies embedded in every website we examined. In total, we detected 174 different types of cookies detected 365 times. Those 174 unique cookies belongs to 87 different companies. There is massive dominance of 4 big US companies: Google (90%), Facebook (46%), Twitter (24%) and Amazon (10%) as well as the Infomediaries Gemius SA (36%), Httpool (7%).
Every time we visit some of those websites, Facebook receives information about our visit and this information is becomes an integral part of the profiling process, a never ending process of creating a clear picture about who you are, what you like and what are your behavioural patterns.
Mobile phone permissions
Even with the use of cookies Facebook is able to get information about your online behaviour, this is just a little part of the information compared to what they can get from your smart mobile devices.
According to our previous research Invisible Infrastructures : Mobile permissions , by installing Facebook, Facebook messenger, WhatsApp and Instagram you are giving access and right to exploit vast amount of different types of data stored on your phone. Some of those permissions are allowing Facebook to extract different forms of information that can be really intrusive such as device identifier, precise location of your device, identity of your contacts, content of your SMS messages, Your call log, record audio, get information about Your WiFi connection, download files without notification and many more.

Other Facebook Companies
At the time of our research, except for the main company, Facebook owned and operated 7 other companies : Facebook Payments Inc., Atlas, Instagram LLC, Onavo, Parse, Moves, Oculus, LiveRail, WhatsApp Inc. and Masquerade. According to them, they may share information about you within their family of companies to facilitate, support and integrate their activities and improve their services. Some of those “family” members are data collector giants as well. WhatsApp alone had over 1 billion monthly active users worldwide as of February 2016. In June 2016 Instagram, another Facebook family member, had reach 500 million monthly active users. Those apps, especially WhatsUp are collecting even more information about user behaviour and activities. Ev en a brief look at the WhatsApp privacy policy or a list of mobile phone permissions, reveals a data collection operation similar in scale to the one that we are investigating within Facebook itself. Specifics to the services that some of those companies provide, the field of data collection is expanded to new frontiers. In the case of Oculus Rift, according to their privacy policy, they can collect and provide Facebook with information about your physical movements and dimensions when you use a virtual reality headset. Facebook Payments Inc. is a company that provides payment services on Facebook, while collecting different set of information, mostly related to your transactions, credit card numbers etc.
Detailed investigation of all the type of data that Facebook can collect through their companies other than Facebook itself will require extended analysis that we will unfortunately have to leave for some other investigation in the future.
Facebook partners
According to FB privacy policy they receive information about you and your activities on and off Facebook from third-party partners, such as information from a partner when they offer joint services or from an advertiser about your experiences or interactions with them.
In April 2013, Facebook launched “partner categories” and incorporated offline and third-party data from data brokers Acxiom (enterprise data and analytics), Datalogix (a digital media and offline purchasing data service), and Epsilon (direct-to-consumer marketing) to all categories of Facebook advertising. According to the New York Times article “Mapping, and Sharing, the Consumer Genome” from 2012, Axciom Corporation servers process more than 50 trillion data “transactions” a year. Company executives have said its database contains information about 500 million active consumers worldwide, with about 1,500 data points per person. That includes a majority of adults in the United States.
These companies collect information about you through things like store loyalty cards, mailing lists, public records information (including home or car ownership), browser cookies, and more. So, if you are buying at Safeway, and use your Safeway loyalty card that information is collected and saved by another Facebook partner company – Datalogix. In December 2014, Oracle Corp. had acquired Datalogix for $1.2 billion. According to their statement, Datalogix aggregates and provides insights on over $2 trillion in consumer spending and have over 650 customers including the top US advertisers and digital media publishers. According to them, with Datalogix, Oracle Data Cloud will deliver the richest understanding of consumers across both digital and traditional channels based on what they do, what they say, and what they buy enabling leading brands to personalise and measure every customer interaction.
Except with the biggest data collectors and dealers at the market, Facebook is exchanging data with hundreds of other data dealers, Ad technology developers, data and marketing analysis companies through their Facebook Partners program.

Another group of organisations that have access to Facebook data are vendors, service providers and other partners that are providing technical infrastructure services, analysing how our Facebook services are used, measuring the effectiveness of ads and services, providing customer service, facilitating payments, or conducting academic research and surveys. Facebook claims that these partners must adhere to strict confidentiality obligations.
In this part of our story we explored different forms and methods of data collection, massive operation hidden behind screens, code, embedded in pixels and cookies, performed by our devices and orchestrated by Facebook.
How this huge amount of data flows further, and how it is used, we will investigate in the next chapter of our story: Facebook Algorithmic Factory (2) : Human Data Banks and Algorithmic Labour
SHARE LAB 2016
Vladan Joler – Research, text, data collecting and visualization
Andrej Petrovski – Research, text and proofreading
Contributors : Kristian Lukic and Jan Krasni
The three stories are exploring four main segments of the process:
Data collection – Immaterial Labour and Data harvesting
Storage and Algorithmic processing – Human Data Banks and Algorithmic Labour
Targeting – Quantified lives on discount
The following map is one of the final results of our investigation, but it can also be used as a guide through our stories, and practically help the reader to remain in the right direction and not to get lost in the complex maze of the Facebook Algorithmic Factory.
In his famous ”Postscript on the Societies of Control” Deleuze envisions a form of power that is no longer based on the production of individuals but on the modulation of dividuals. Individuals are deconstructed into numeric footprints, or dividuals,that are administered through “data banks” .
 17th century engraving of the pons asinorum in logic
17th century engraving of the pons asinorum in logic
Research tools and methodology : how data is stored and what kind of algorithms are inside is the hardest part to investigate. Luckily we found a source of knowledge that gave us some kind of insight into those mysterious algorithmic processes: database of all publicly available Facebook patents. We found around 8000 different patents registered by Facebook. Based on them we created possible interpretation of what happens within the black box. Another lead and source of information for us was Facebook Graph API, primary way for third party developers to get data in and out of Facebook’s platform.
Storing Data
Before we explore different ways how Facebook stores and analyses our data, it is important to understand the concept of social graph, a meta structure connecting all data into one structure.
Social Graph : One Graph to Rule Them All
The story of the Social Graph is the story of domination and ambition to rule the World of Metadata by interconnecting every piece of information within and outside of the Facebook Empire into one single graph. “It’s the reason Facebook works.” Said Mark Zuckenberg in 2007 attributing the power of Facebook to the Social graph.
A Social Graph is how Facebook represents all its data, and it’s basically about two things : Objects, also known as nodes and Connections that describe the links between these nodes also known as Edges
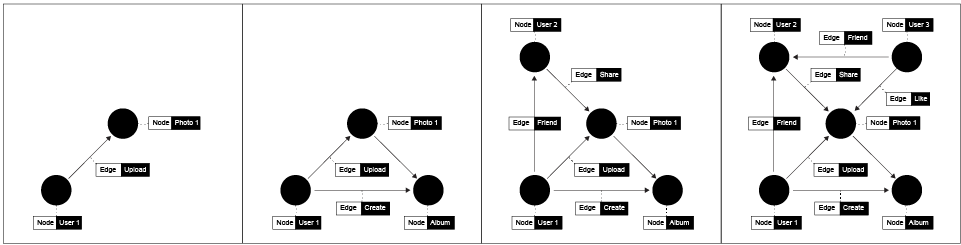
Every user, place, photo, group, event, everything created on or uploaded to Facebook is a unique object in the Facebook database with its own ID. For example, when you like some picture on Facebook, a connection <like> is created between the two objects, you <userID> and photo <photoID>. This photo can have many other connections, i.e. other users that liked the same photo, location associated with that photo or users that are tagged on that photo.
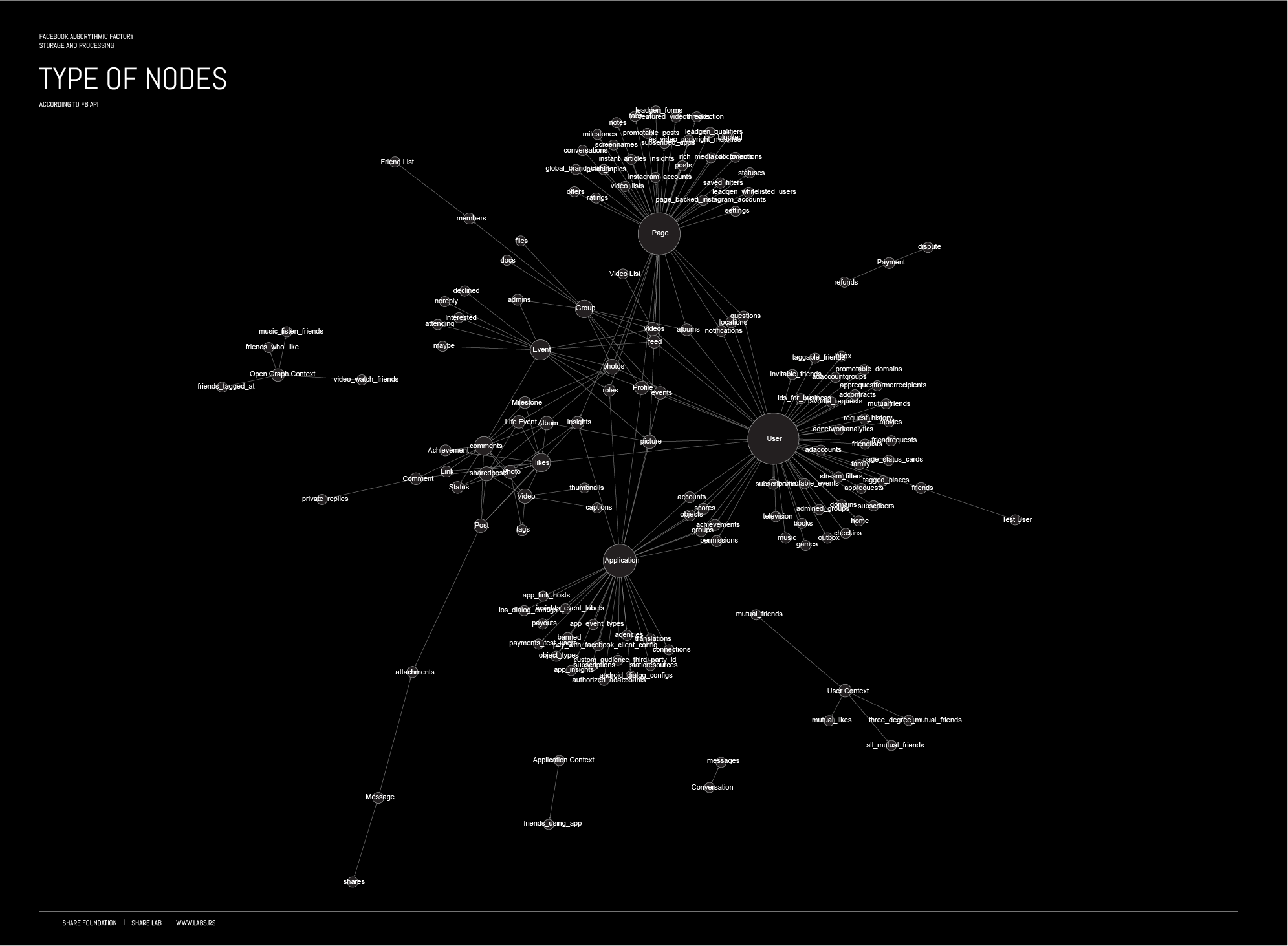
According to the Facebook API, there are the different types of nodes that exist within the Facebook social graph:
By using a social graph, Facebook is able to relate different users that have liked the same photo or relate people that are tagged on the photo with the location attributed to the photo.
the Facebook universe is a vast social graph made of billions of objects, interconnected by different kind of links.
Feeding the Social Graph
According to dozens of Facebook patents there are 3 different stores, databases that feed the Social Graph, and store all the data, metadata and content we create.
Action store maintaining information describing users’ actions.
Content Store – stores objects representing various types of content.
Edge store – stores the information describing connections between users and other objects
Content Store and Edge Store together are basically a database, structural resource for main meta structure, Social Graph connecting all objects and connections into one structure.
All our actions on Facebook are recorded by Action and Content Loggers that feed the Action and Content stores with new data, constantly expanding the data bank about us, owned by Facebook and potentially shared with many.
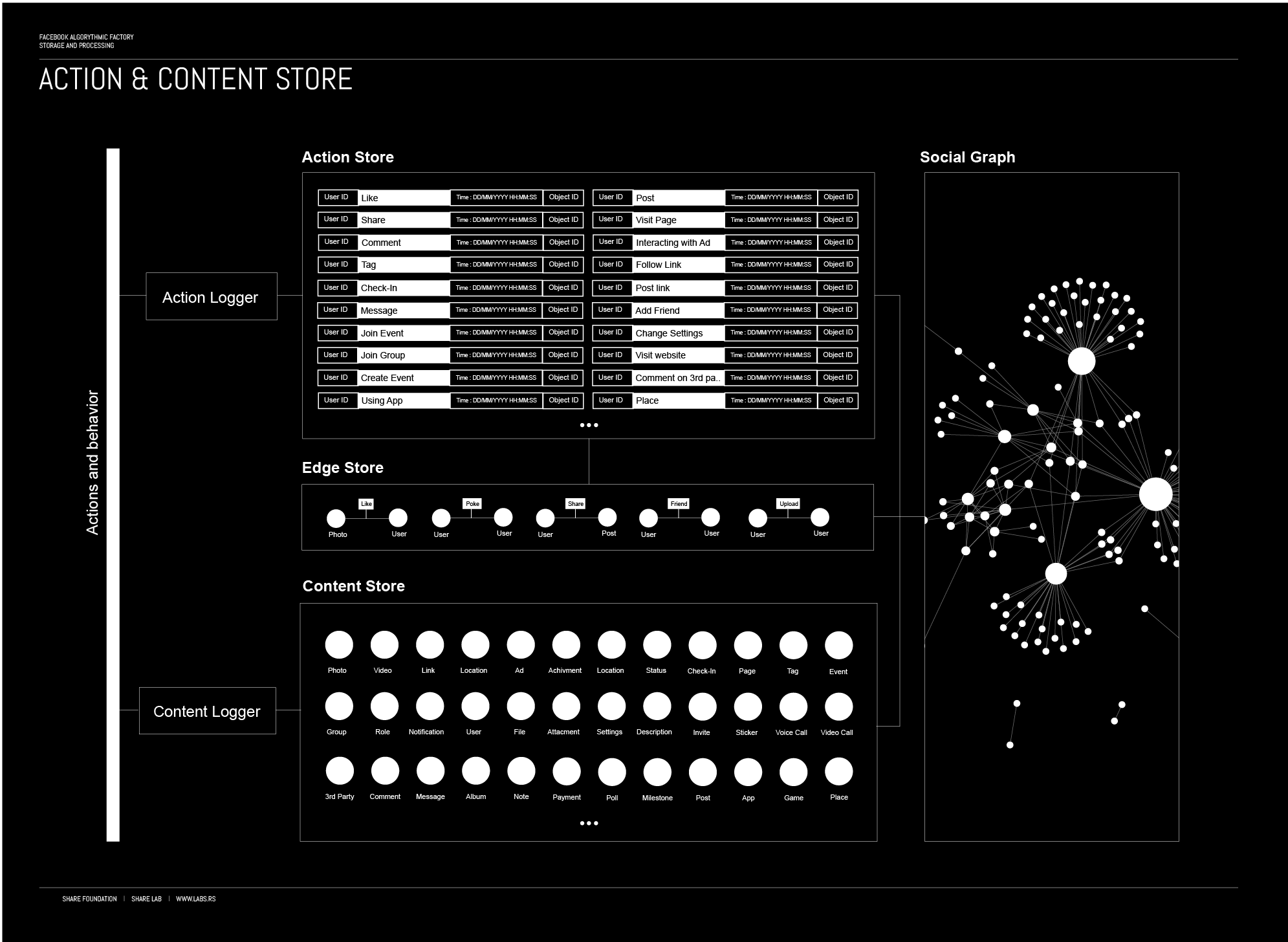
Action Store
Every click, like, share and basically whatever you do on Facebook is collected by an action logger and stored in the Action Store. The action store maintains information describing actions by users, as well as actions performed on third party websites that communicate information to the Facebook. Users may interact with various objects, as we explained before, maintained by Facebook, and these interactions are stored in the action store.
Examples of actions or interactions include: commenting on posts, sharing links, tagging objects, and checking-in to physical locations, commenting on a photo album, transmitting messages to another user, joining an event, joining a group, becoming a fan of a brand page, creating an event, authorizing an application, using an application, interacting with an advertisement, and engaging in a transaction.
Content Store
The content store stores objects representing various types of content such as page post, a status update, a photo, a video, a link, a shared content item, a gaming application achievement, a check-in event at a local business, a brand page, or any other type of content. Objects may be created by users or in some cases received from third-party applications (other websites or apps).
Edge Store
The edge store stores the information describing the connections between users and other objects. Some edges may be defined by users, allowing users to specify their relationships with other users. Other edges are generated when users interact with objects, such as expressing interest in a page, sharing a link with other users, and commenting on posts made by others. The edge store also stores additional information, such as affinity scores for objects, interests, and other information generated by the algorithmic processing that we will cover after.
Profile Store
As we already mentioned, our action data is collected and stored in the action, content and edge stores. On the other hand the information that we are share about ourselves in the profile information section are stored in Profile Store.

Each user is associated with a user profile, which is stored in the user profile store. A user profile includes declarative information about the user that were explicitly shared by the user and may also include profile information inferred by other means of data collection and analysis performed by Facebook. A user profile may include one or more direct characteristics that uniquely identify a user associated with the user profile such as e-mail address or a phone number. Those information can be used to identify user outside of the Facebook domain, indicates that the user profile and the additional user profile are associated with the same user.This allows Facebook to track users and merge information from other sources. Combined with Facebook’s “real-name system” that is dictating how people register their accounts and configure their user profiles, they can more or less accurately connect your user profile with your real identity. “Facebook is a community where people use their real identities. We require everyone to provide their real names, so you always know who you’re connecting with”
Those structures are buildings of the Facebook Factory, architecture where resource materials, data that is extracted from our behaviour is stored and prepared for the algorithmic workers to deal with. In next chapter we will explore the anatomy of some of the most interesting Facebook workers – algorithms that are transforming behavioural data into a final product.
Processing of data : Anatomy, tasks and responsibilities of an Algorithmic Labourer
Understanding how algorithms process vast amount of data and what is it exactly they do is of great importance for understanding the forms of possible exploitation of our personal data and mechanisms of manipulation on a large scale influencing billions of people every day.
One of our main goals in this research was to try to have an independent insight into those processes and we tried to come up with different methods for measurements or potential methodologies for independent audit of algorithms from the outside, but we faced a lot of difficulties. Nevertheless, even though we didn’t manage to create a methodology based on actual data, our research of Facebook patents gave us an insight into some of the most important processes.
What is an algorithm? Although for the purpose of storytelling it would be much more appealing to attribute algorithms with some superpowers, in most cases, we speak about some really amazing piece of code that applies some advanced statistical or analytical methods. The definition of an algorithm is: A procedure for solving a mathematical problem in a finite number of steps that frequently involves repetition of an operation; broadly: a step-by-step procedure for solving a problem or accomplishing some end especially by a computer.
 Euclid – Detail from the painting “The School of Athens” by the Italian Renaissance artist Raphael created between 1509 and 1511
Euclid – Detail from the painting “The School of Athens” by the Italian Renaissance artist Raphael created between 1509 and 1511
Action data analysis
As it was explained before, each and every activity on Facebook is being stored in the so – called Action store. That means that the action store is a huge, structured dataset of user activities, making it a quite convenient choice for a targeting mechanism.
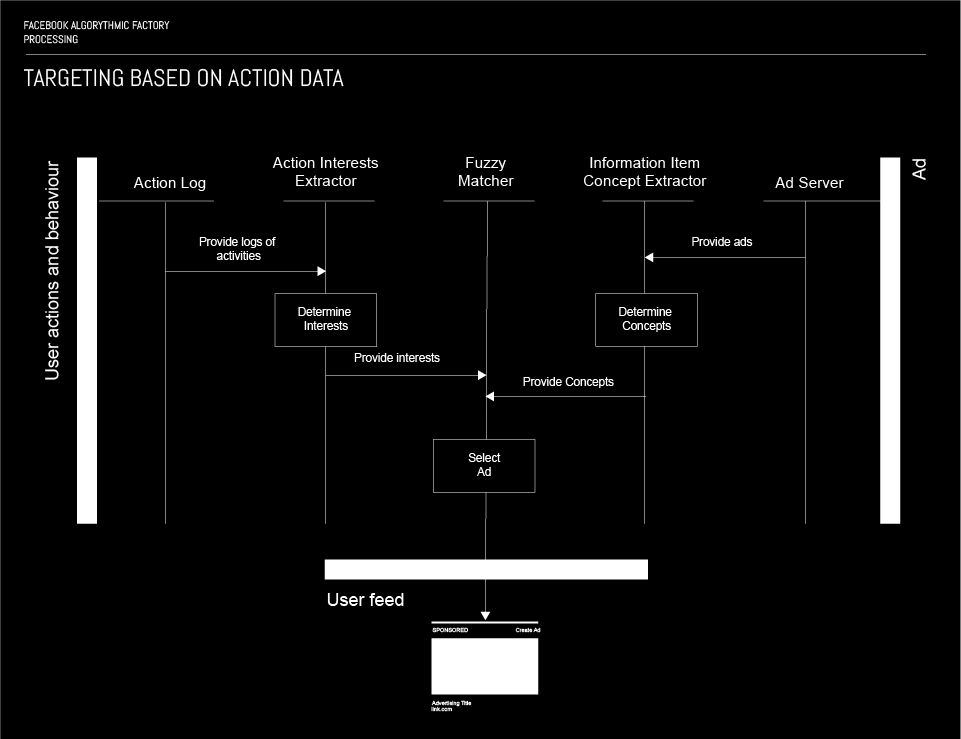
A Fuzzy matching algorithm is used as a principal mechanism for targeting based on data from the action store. Two parallel processes take place in order to generate the input for the fuzzy matcher. First, the activities logs are obtained from the Action log, by Action Interest Extractor. Once these logs are loaded in the Action Interest Extractor, the list of interests of the specific user is determined based solely on data from the Action log, i.e. his activities (clicks, likes, comments, shares, etc…). Then, the list of interest is forwarded to the Fuzzy matcher, as a query.
The second process is the process of selecting the adequate ad for the user that is being targeted by the Fuzzy matcher. The first step in this process is the Ad server providing ads to the Information Item Concept Extractor. Once a set of ads is loaded by the Information Item Concept Extractor, they are analysed and each ad has its concept determined, i.e. each ad is being assigned an attribute representing its concept.
Finally the Fuzzy matching algorithm performs a search, using the interests as a query; as a result selects an ad that makes the best match to the query, which is then being served to the targeted user.
Content analysis
In the previous couple of paragraphs, the mechanism of targeting users by using data from the Action store was explained. Apart from that data, data from the Content store are also being used for targeting users. Needless to say that in this case the targeting is based on contents users publish on Facebook in several different ways.
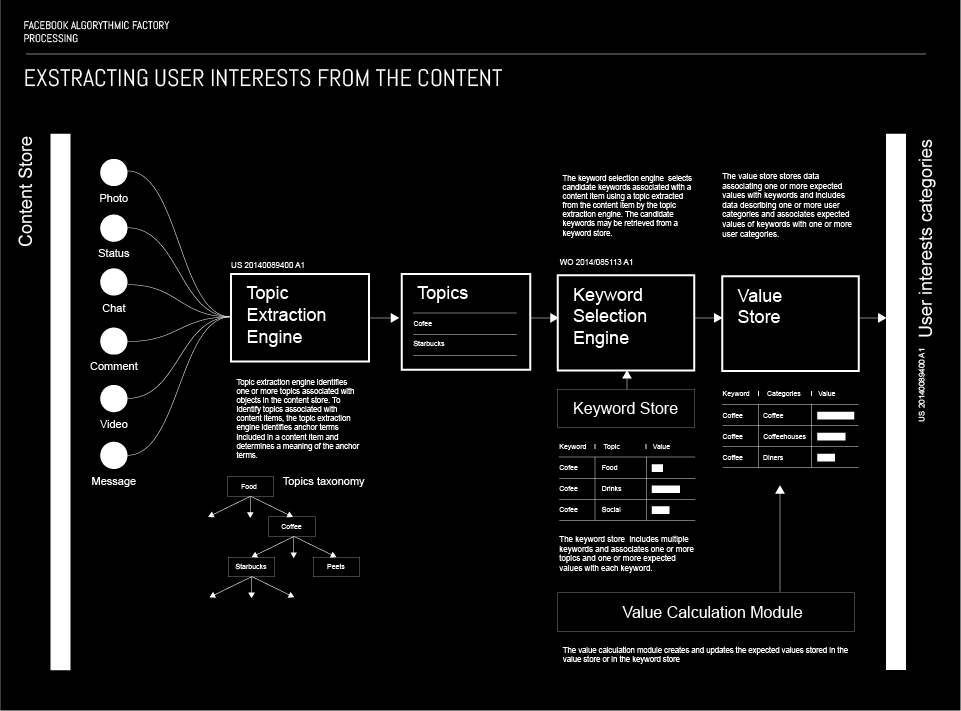
There are two relevant aspect of targeting based on content. The first one are the topics, and the second one are the keywords. When a user posts some sort of content to Facebook, there is a Topic extraction engine that identifies one or more topic associated with the content. In order to associate the topics with the content, the extraction engine analyses it and identifies anchor terms included in the content and determines the meaning thereof.
More about this processUsing the extracted topic, an algorithm defines a list of keywords and associates them one or more expected values. The algorithm uses information about the user to determine the values associated to the candidate keywords on the list. The assigned values are used for ranking the candidate keywords, with the highest ranking being chosen as one the most precisely defines the content.
When choosing what content, i.e. ads will be served to the user in the future, the algorithm uses the links created between the user and the keywords from the content.
An important input for content based targeting also comes from the Action store, and it’s related to negative signals to ad targeting. This is in fact a set of content that the user might have a negative sentiment towards, and is used to label ads that the users would not like to see. When Facebook determines, based on the user’s actions that they dislike particular object (content), it determines the topic of the object and associates negative sentiment to them. The association between negative sentiments and topics is used to decrease the likelihood that an ad matching the said topic will be served to the user.
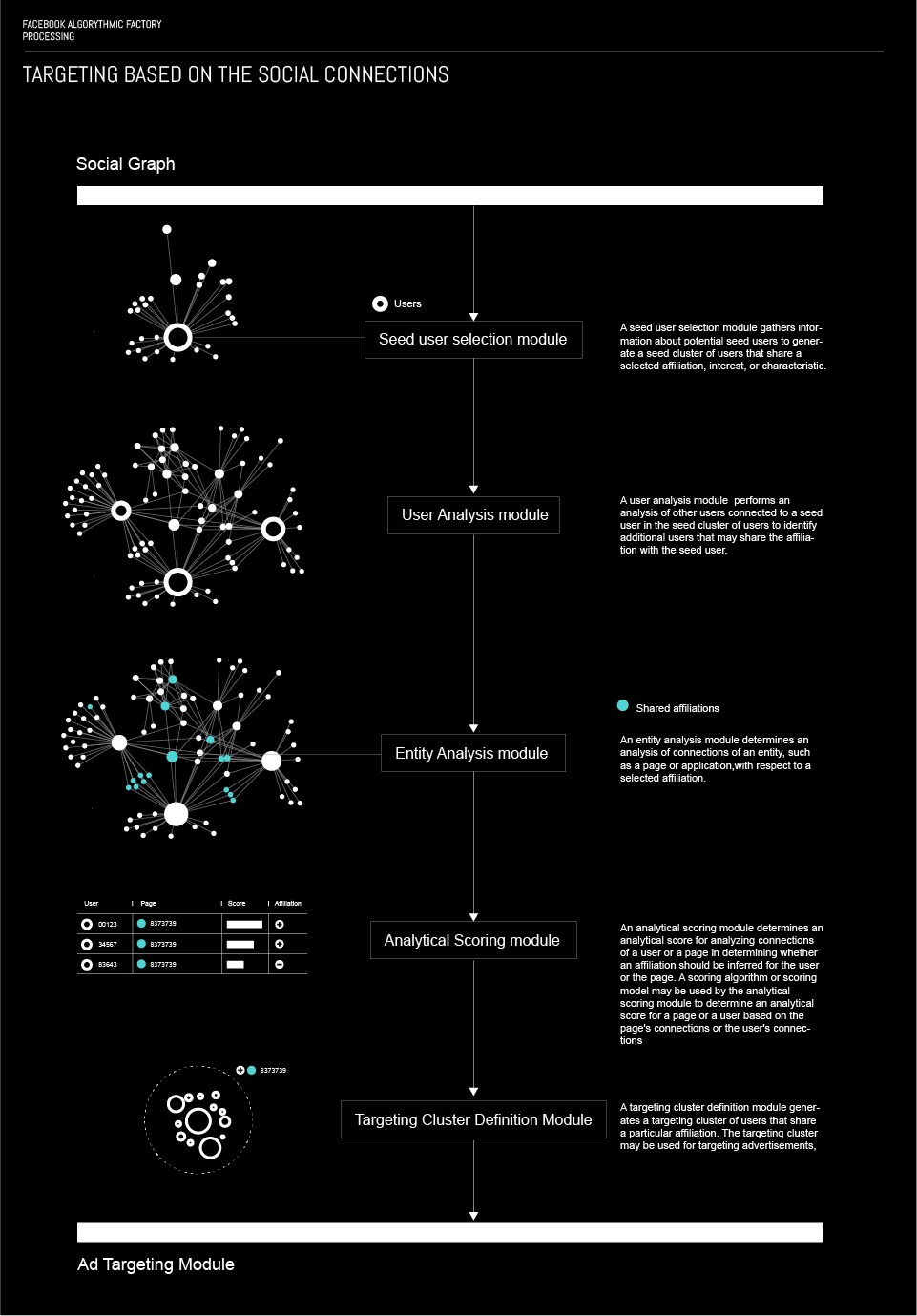
Important data for precise targeting is gathered by forming logical structures of users. Facebook, groups users who share a particular attribute into a structure called seed cluster. Once a seed cluster is created, a set of other users or objects that the user is related to is retrieved. Within these sets, an algorithm determines whether the users in the set share the same attribute as the primary user. The process of determination is based on explicit declaration of the secondary user, analysis of their connections and uses a random walk algorithm. The results are used to decide if the secondary user can also be associated to the cluster. As a result, a targeting cluster is established, and can be used for targeting users and showing them specific ads.
More about this processThe credibility of these clusters is tested by measuring click-through rates of users in the cluster for a particular ad or measuring negative feedback of users in the cluster. In addition to this, users can be put in a cluster based on their interactions with pages, applications etc.
The process of forming groups and subgroups, uses several different modules. First of all, the seed user selection module, which gathers information on potential seed (primary) users and creates a seed cluster of users who share a particular affiliation, interest, or characteristic. In the first stage the algorithm selects users that have explicitly stated these attributes on their profiles (like a page or the likes). However, activities, such as likes, comments, check – ins etc. related to the user can be used for clustering.
A second module is used to make subgroup based on the members of the group (users already in the cluster), by exploring their activities and attributes and checking whether they could form a part of the group. The process of data gathering for these secondary users is similar to the one used on seed users.
The entity analysis module is used to determine attributes of users based on their interactions with pages or applications. For instance if somebody supports a certain political party, the algorithm presumes that they would be interested in a certain types of cars, because most of the users that use a facebook application that shows the nearest selling points for said cars, support the said political party. What this module does is it groups people based on what objects they interact with and what type of users most often interact with such objects.
Some attributes of the user can be determined by evaluating their connections to other users. This is done by the analytical scoring module. This module determines particular attributes of the user by scoring their connections to other people. For instance, if a user has a few weak connections to other users that like white wine and stronger links to users that like red wine, this module would based on the strength on the connections (probably based on mutual interactions, check-ins, tags etc) will consider the primary user as one that likes red wine.
Once certain attributes are determined by the four aforementioned modules, a targeting cluster definition module generates a cluster of users sharing the same attributes. The clusters are used for serving specific types of ads, but also for specific targeting of content that the user is likely to enjoy seing. This way, besides generating revenue, Facebook, also controls the information flow to the user, based on preferences, that a set of algorithms has established. In a way, that could be considered censorship.
The process of forming groups and subgroups, using the aforementioned modules, as a complete flow has several steps. First of all users are structured into subgroups based on a similar attribute; then a centroid (a central user) of the group is identified, and through them, the characteristic of the entire group are identified. All the users in the subgroups are then ranked by the similarity of their attributes, to the ones of the central user i.e. the subgroup. Finally the subgroup is labeled as a whole, compact unit; for example, people who like red wine and Harry Potter.
TARGETING USERS BASED ON EVENTS
This algorithm performs event targeting based on several different criteria. The first and most simple criterion that could indicate an association of a user with an event is the RSVP option on the events created on Facebook. However, since users can RSVP yes, but not attend an event, the algorithm can calculate whether they will really attend the event based on their previous attendance score, the number of their friends attending and the general event history. Additionally the algorithm uses other inputs, such as a check-in at the event venue, uploading a photo of the tickets for the event, record of purchasing tickets on an external website or tagging the event in a post. Event targeting is used on events on all scales from small, private events to global events.
More: PATENT WO2013074367 (A2)
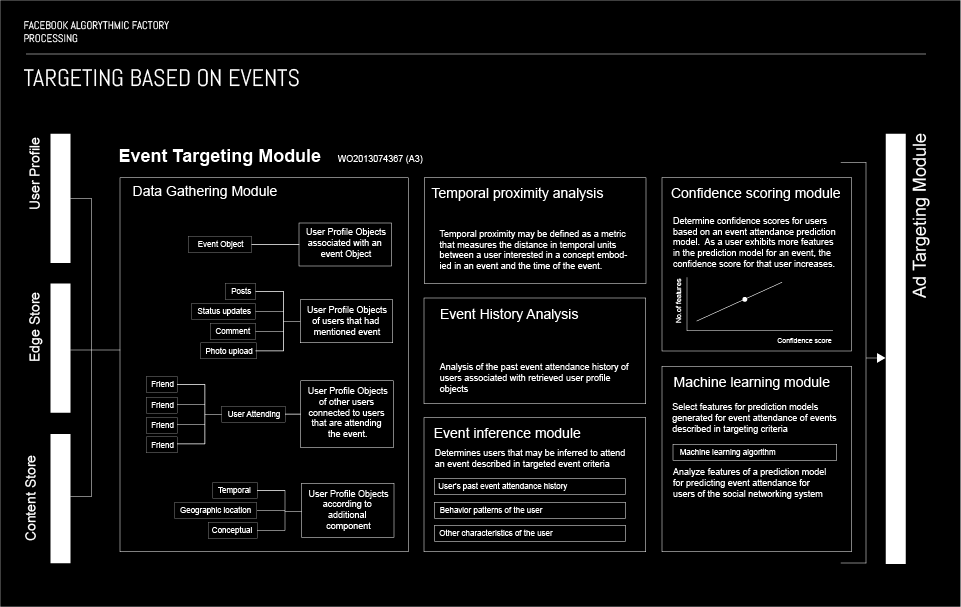
Targeting objects to users based on search results in an online system
This algorithm makes use of the query users input into the search box on Facebook. The purpose of this algorithm is to serve the user with ads that correspond to their search query. As the use inputs the query in the search box, results matching the query are compiled, while the algorithm tries to recognise a structured nodes in the query and in the results. Then. it retrieves ads that correspond to the recognised structured node and at the same time retrieves information about the user. After matching the ads to the user’s information, i.e. attributes, it determines which ads should be shown with the results of the query. This practically happens as the user types in the query, so it is quite hard to perceive it as something so well structured.
More: Patent WO 2014099558 A2
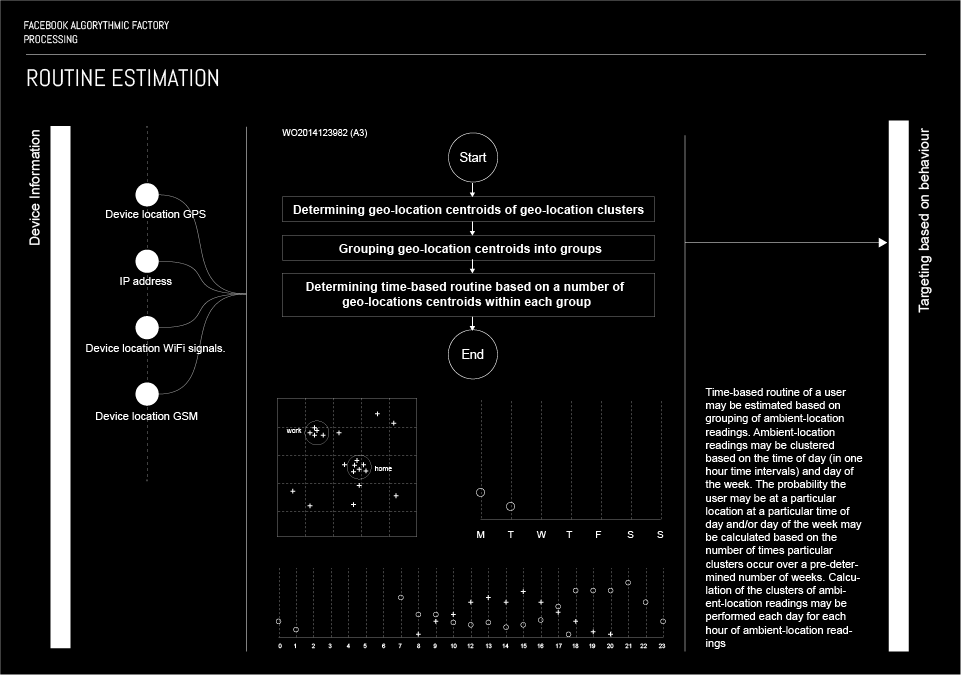
Routine estimation
This algorithm determines the routines of a user by analysing the geolocation of a user over a period of time in hourly intervals. The algorithm uses data about user’s geolocation provided by mobile devices, such as smartphones, tablets or laptops, or rather sensors installed in these devices, i.e. GPS sensor, gyroscope or a compass; the Facebook app installed on the device gathers the necessary data and feeds them to the algorithm. Next, the algorithm analyses the repetition, or the user being at the same location at a certain hour on a certain day of the week. The algorithm then clusters these geolocation centroids; afterwards the clusters are labeled by a place that corresponds to the geolocation centroids in the cluster. In that manner, the algorithm can determine where the user lives, where they work, if they go to the farmer’s market on a saturday morning, do they go to the gym and how frequently etc.
More : Patent : WO 2014123982 A3
Inferring household income for users
This algorithm maps a user into a particular income bracket. This is done through analysis of the information the user provides, i.e. Current and past work positions, current and past education institution they have attended, life events, family relations and marriage status. However, since users have the ability to provide false information to Facebook, this algorithm further analyses user’s behaviour, websites they visit, purchases they make online etc. The algorithm uses different techniques to map the user in a particular bracket, including image analysis to recognise brands the user wears on photos they upload, how often they use brand names in posts and searches etc. These information is then used to enable advertisers to easier target their appropriate target group by income. Also, the machine learning algorithm has the ability to detect when users have given faulty information or have forgotten to update their information, such as change of workplace, moving to another city marital status and the likes.
More: Patent US 8583471 B1
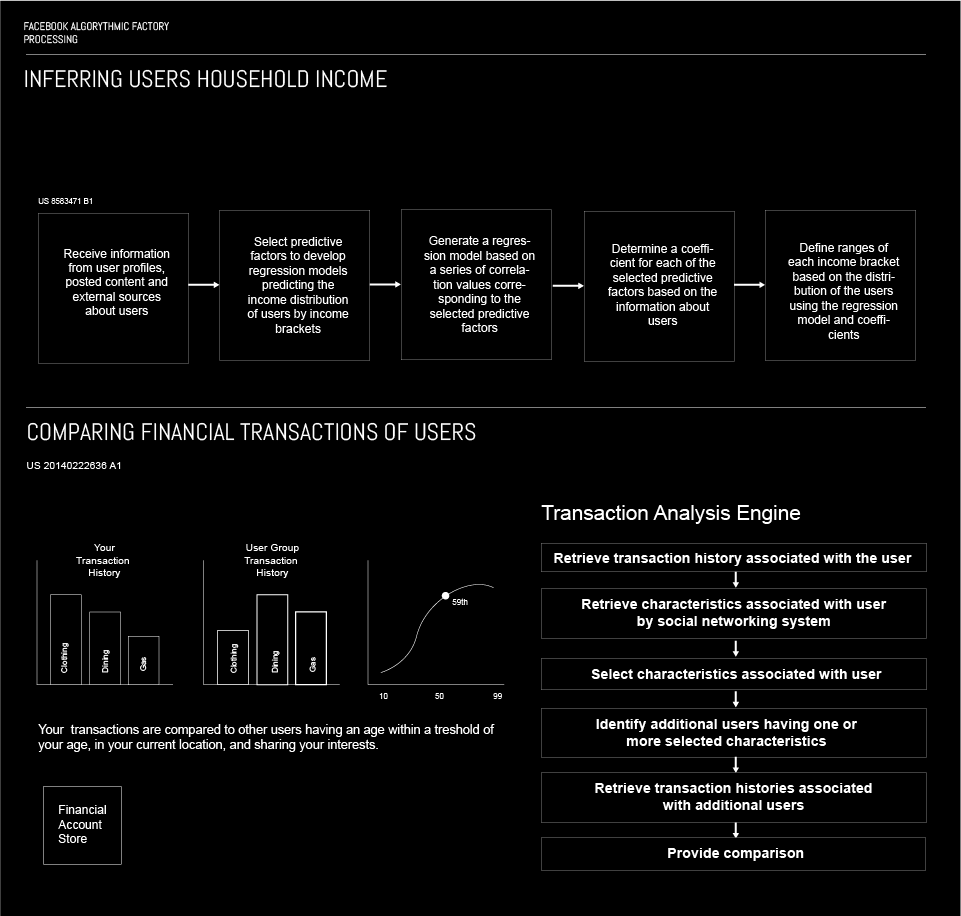
Comparing Financial Transactions Of Users
What this algorithm does is comparing the buying habits of a user compared to a group of users the user can be associated with by sharing similar attributes, such as age, location, education level, work position etc. The algorithms analyses search queries, visits to external websites and other types of transactions within Facebook and on third – party websites. Using this data, the algorithm can provide the user with analysis of former transactions, but can also predict future spendings, for example it can predict how much would a user spend on travel by comparing his previous transactions to other users that share similar interests, have the same age and live in the same city as the primary user.
More: Patent US 20140222636 A1
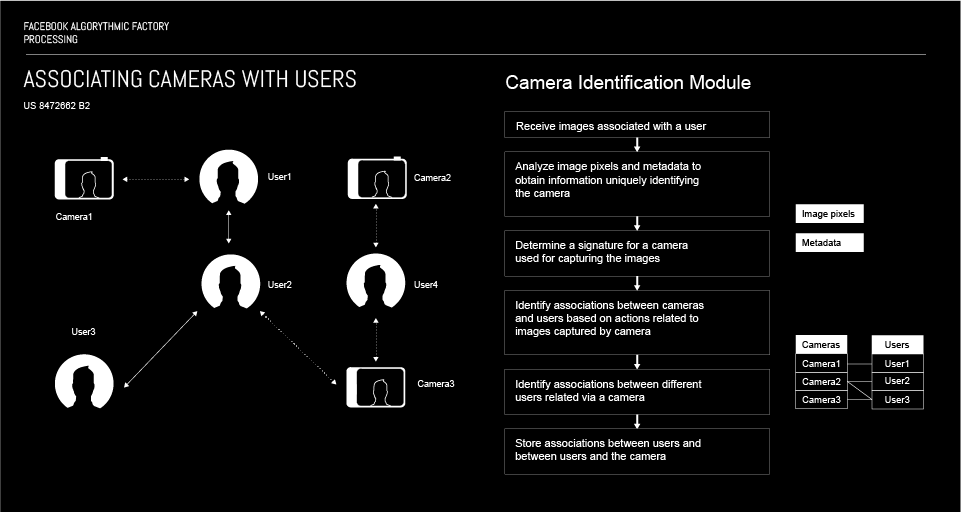
Associating cameras with users of a social networking system
This algorithm associates Facebook users based on pictures and/or videos taken using the same camera, i.e. device. When photos or videos are uploaded on Facebook, the UI, camera signature is red by the algorithm and it serves as a connection point for users uploading photos or videos taken using the same device, i.e. camera. This can be used for detecting fake accounts, a user having multiple accounts; but also for the purpose of a social graph, i.e. recommending friends, prioritising news feed, etc.
More: Patent US 8472662 B2
There are some, in our opinion, interesting and relevant algorithms that are used in the process of quantification and monetisation of our everyday life. The featured algorithms are just few examples of probably hundreds and hundreds of different algorithms that try to understand every our action and post, classify us into nano-sub categories and predict our future behaviour. We encourage the readers of this text to explore by themselves the available patents and continue this research in order to understand this phenomenon.
In the third and final part of this story, Targeting – Quantified lives on discount, we will explore the form of the final product of the Facebook Algorithmic Factory and discuss issues and problems related to mapping the Facebook Empire.
SHARE LAB 2016
VLADAN JOLER – RESEARCH, TEXT, DATA COLLECTING AND VISUALIZATION
ANDREJ PETROVSKI – RESEARCH, TEXT AND PROOFREADING
CONTRIBUTORS : KRISTIAN LUKIC AND JAN KRASNI
]]>
The three stories are exploring four main segments of the process:
Data collection – Immaterial Labour and Data harvesting
Storage and Algorithmic processing – Human Data Banks and Algorithmic Labour
Targeting – Quantified lives on discount
The following map is one of the final results of our investigation, but it can also be used as a guide through our stories, and practically help the reader to remain in the right direction and not to get lost in the complex maze of the Facebook Algorithmic Factory.

Targeting : Quantified liVes on discount
“In their now classic study of traditional media, Manufacturing Consent, Herman and Chomsky explain the basic business model of newspapers as being the production of an audience for advertising. Their analysis suggests the counterintuitive notion that publishers’ main product is not the newspaper, which they sell to their readers, but the production of an audience of readers, which they sell to advertisers. In short, the readership is their product.”
The difference between Facebook and traditional media is that on Facebook there is no readership in general, but the an algorithmic labour and production within the Facebook Factory which allows them to profile and sell each user as an different product.
In order to map this process we examined the structure, categorisation and targeting methods available to advertisers through Facebook. There are 3 main categories of targeting options, user profiling based on basic information (location, age, gender and language), detailed targeting (based on users’ demographics, interests and behaviours) and connections (based on specific kind of connection to Facebook pages, apps or events). Every user is basicly profiled and tagged with the use of those three methods and is being offered as a target for advertising. Facebook’s revenue ($ 17.93bn in 2015) directly depends on the user profiling quality. The more accurate the user profiles are, the better product offered to advertisers they become. The ultimate product of Facebook’s surveillance economy is a deep insight into your interests and behaviour patterns, exact knowledge who you really are and prediction how you will eventually behave in the future, packed in user profiles.
Connecting the dots
It is important to say that the left side of the presented visualisations is based only on our assumptions. According to the list of different types of data collected by Facebook and different algorithms, databases and meta structures that we featured in previous segments of our research, we tried, using our logic to make conclusions and to relate different targeting methods with matching data sources and algorithms.
For example, if on the Targeting side we have targeting based on <user gender>, we can easily relate, connect this with <gender> information provided by the user in the Profile Information section on the Input side of the graph. But, in most cases, it is not as simple as that.

Basic targeting is mostly based on information provided by users in the Profile information section, except location that can be determined in multiple ways using the digital footprint of our devices. Targeting based on Connections can be based on data from the Social Graph and Action data.
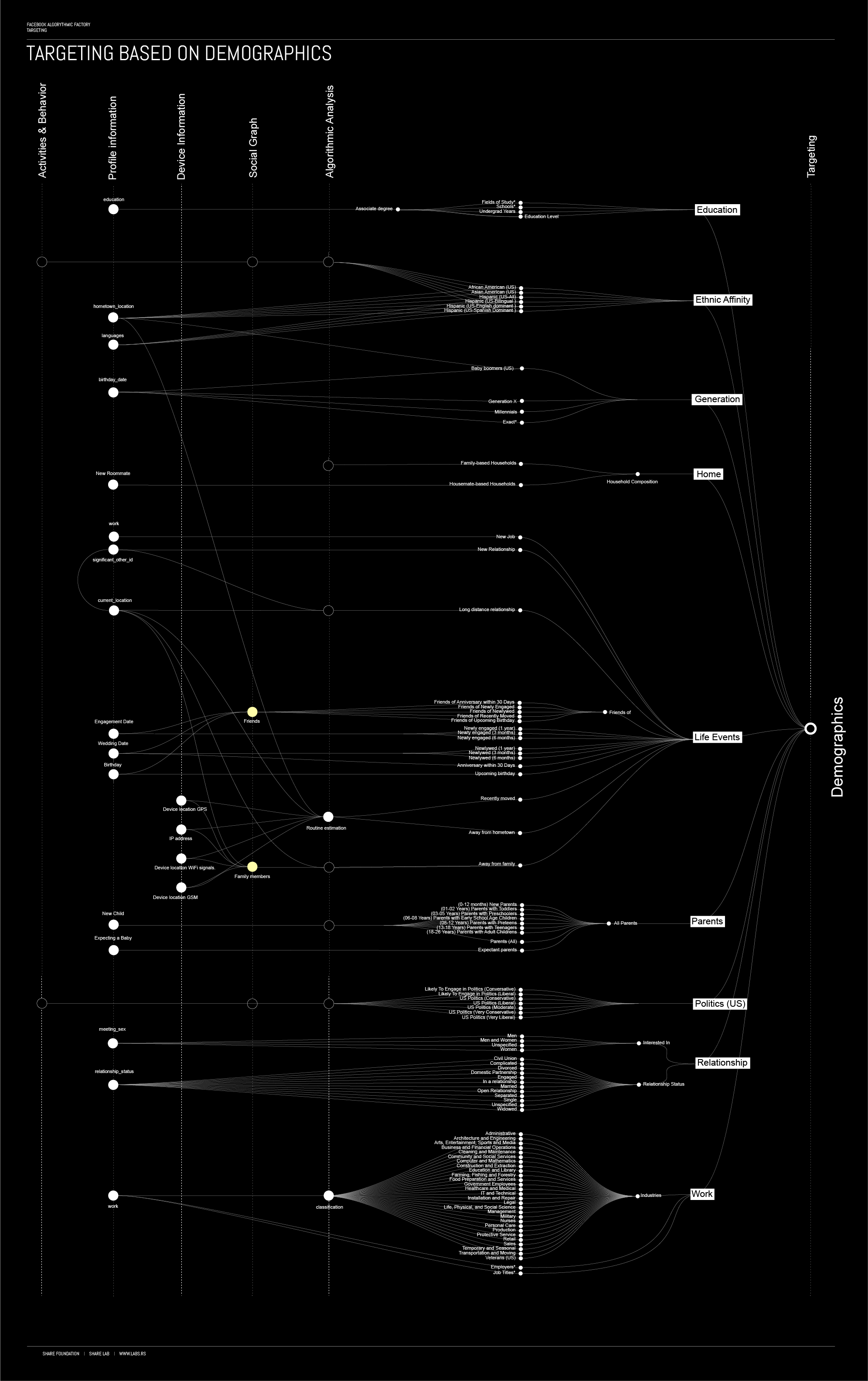
Our assumption is that Targeting based on Demographics is mostly based on profile information, but there are few interesting cases that can be potentially subject of further investigation.
For example, Facebook offers among other categories, targeting based on ethnic affinity and as one of the option, they offer targeting of US Hispanic, African-American and Asian-American clusters. They have explained that this is based on actual users who are interested in or will respond well to Hispanic content, based on how they use Facebook and what they share on Facebook. To be able to cluster users into this kind of categories, they probably use analysis of users’ social connections in the social graph. However, a legitimate question to Facebook at this point would be, how African-Americans use Facebook in a different manner that can be tracked compared to Asian-Americans?
Another interesting and potentially unethical targeting method is something that they call targeting based on Life events. Here you can be targeted not only based on your behaviour but based on the behaviour and actions of you friends. So, for example you can be a target of advertising if the people in your social network are engaged in certain topics. This is a clearly great example of the power of the social graph analysis.
An excellent example of how hard it is to avoid targeting on Facebook, if we consider for example the Parents category, is an experiment from a Princeton sociology professor, Janet Vertesi who tried to see if it is possible to prevent Facebook detect she was pregnant.
In light of the recent discussions related to the power of Facebook manipulating voter behaviour during election time, One category in this section drew our intention: politics
Facebook offers targeting of US users based on their political views (conservative or liberal) and on a scale from likely to engage in politics, over moderate to very conservative or liberal. The clue on how Facebook can perform this kind of analysis and draw this kind of conclusions about each user can be found in a segment of our research Targeting based on the social connections and in patent – Inferring target clusters based on social connections (US 20140089400 A1) .
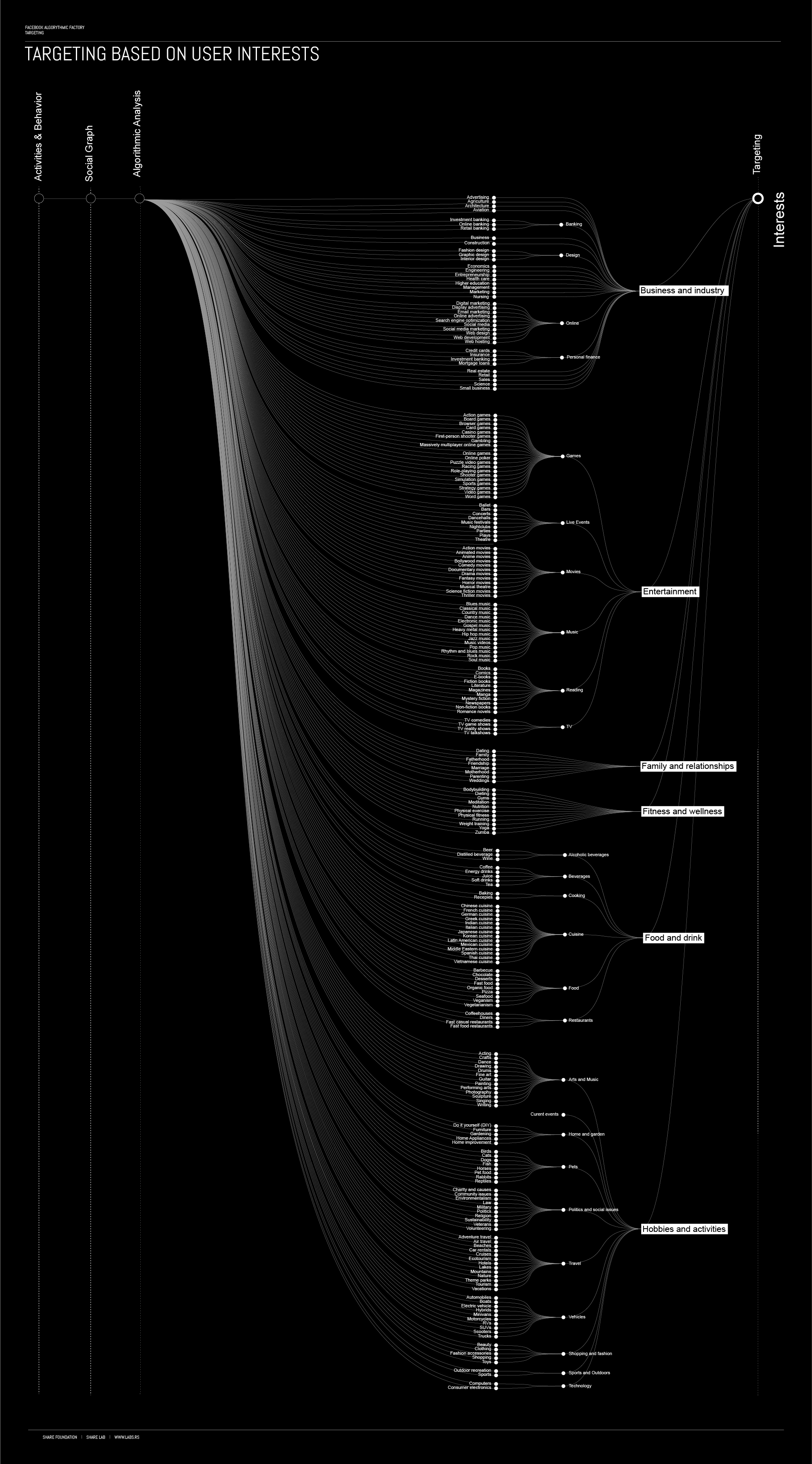
Targeting based on the user interest is by our opinion solely based on the process of Action data and Content analysis. As we explained before, during this process, keywords and topics are extracted from the user content and each content is basically tagged with associating keywords and topics. Interaction and actions of users related to content is then matched with the use of the fuzzy matching algorithms with the ads in different categories and subcategories.
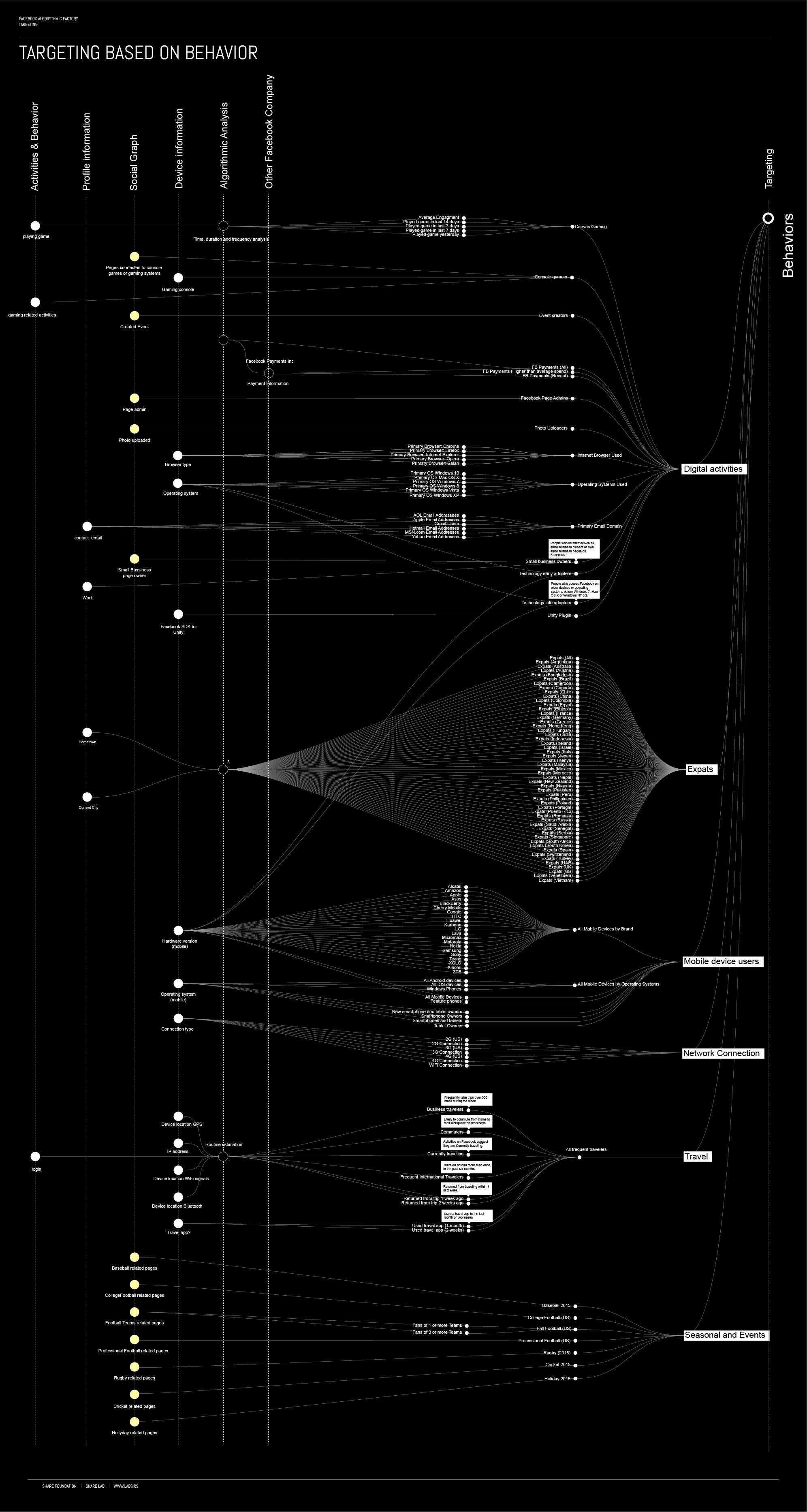
Targeting based on Behaviour is really diverse with different types data sources used for analysis.
The digital activities section is mostly based on the analysis of the digital footprint of your devices in combination with other forms of data from user actions and social graph. Facebook is tries to cluster users based on the devices or applications they use, frequency of content types that they create or time they spend playing games for example.
The most intriguing targeting option in this segment for us is – All frequent travelers section. Here Facebook offers targeting of Business and International travelers, Commuters, users who are currently traveling or users that returned from trip one or two weeks ago. It is clear that in order to perform this kind of targeting, Facebook needs to engage in location tracking of users and to analyse patterns of user behavior. Traces of how this is done can be found in patent WO 2014123982 A3 Routine estimation. This patent explain the analytic method of user geolocation data collected from devices over a period of time in hourly intervals. The algorithm analyses the repetition, or the user being at the same location at a certain hour on a certain day of the week. The algorithm then clusters these geolocations and labels them by a place. The algorithm can determine where the user lives, where they work, are they commuters or currently traveling abroad.
Another interesting segment is related to the analysis of financial transactions. In the previously explained patents: Inferring household income for users of a social networking system (US 8583471 B1) and Comparing Financial Transactions Of A Social Networking System User To Financial Transactions Of Other Users (US 20140222636 A1) we can find out how Facebook clusters users into particular income bracket. This is done through analysis of the information the user provides, i.e. Current and past work positions, current and past education institutions they have attended, life events, family relations and marriage status, user’s behaviour, websites they visit, purchases they make online. The algorithm uses different techniques including image analysis to recognise brands the user wears on photos they upload, how often they use brand names in posts and searches etc.
Outro : Cartography of Facebook Empire
Cartography, has been an integral part of the human history as an essential tool for humans, to help them define, explain, and navigate their way through the world. Most of the ancient maps, from the perspective of the GPS and satellite imagery enhanced present look like inaccurate and naive representation of the world, but they are the technological, scientific and artistic state of the art of their time. They are a clear representation of will and necessity to understand the world around us.
The Fra Mauro map, from around year 1450 by the Italian cartographer Fra Mauro. Source : Wikipedia
{kind=link}
Our capacity to map the Facebook Empire is similar to the effort of the ancient cartographers that travelled, observed and measured distances without any sophisticated tools and technologies whatsoever. In the same manner we like to think that the map of the Facebook algorithmic Empire we presented here is similar in precision to some ancient maps of the world. But, this can be a really optimistic idea. As opposed to geographical data, that change quite slowly, the shapes of the Facebook Empire change on daily basis. New algorithms and categories are being introduced, the system is tuned regularly, new components are being added. And all of this inside of the black box.
The patents that we examined and are publicly available are from different times and the methods explained in them are probably already replaced with new ones. To make the situation even worse, the patents become publicly available two years after they have been submitted. And two years in the world of the algorithms is like centuries. This is just a small portion of the problems around the idea of the algorithmic transparency.
For 36 minutes, from 2:32 pm until 3:08 pm on May 6th, 2010, the trillion-dollar stock market crashed (a crash known as Flash Crash), which was one of the most turbulent event in the history of financial markets.Caused by black-box trading, combined with high-frequency trading, resulted in the loss and recovery of billions of dollars in a matter of minutes and seconds. Regulatory bodies and the academic community investigated this few minutes long event for years in order to understand what happened in just a few seconds of this algorithmic madness. This brings us to the question of our capacity to independently audit algorithmic processes and black boxes that shape our world.
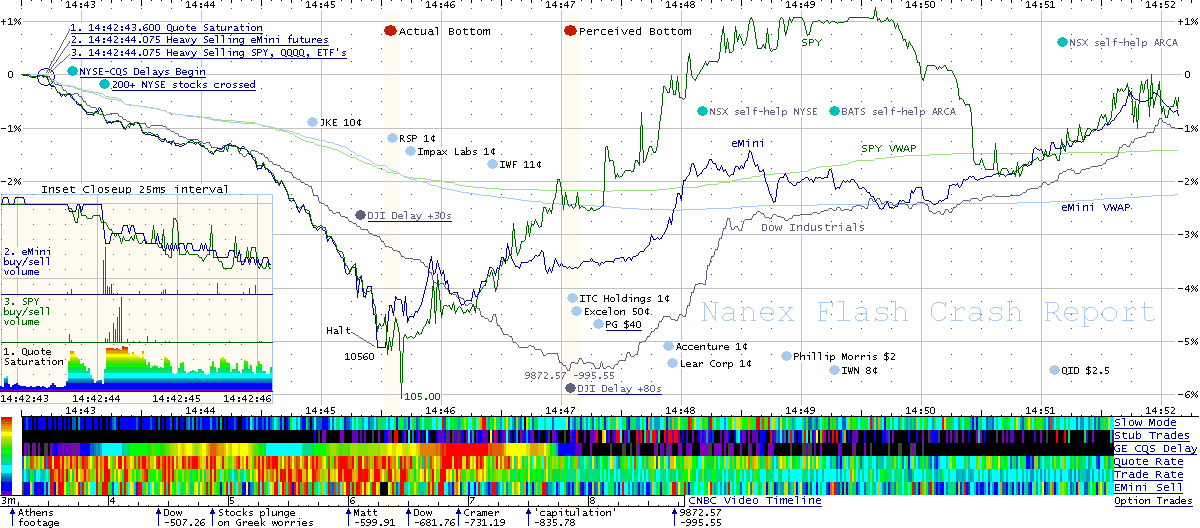 Source : Nanex Flash Crash Summary Report
Source : Nanex Flash Crash Summary Report
It is not so unreasonable to believe that even inside Facebook, there is no one who really has a full map of all the algorithmic processes that are happening at this very moment. Some of those algorithms are products of the brilliant minds and expertise of the most educated experts in the field that money can buy and it is hard to believe that any independent body will ever be able to oversight those algorithms in reasonable time and budget.
On the other hand, any kind of insight, any kind of map that can even superficially draw the shape of those complex processes can be considered a significant step into better understanding the algorithmic world around us. We see the outputs of this investigation as an advocacy and educational tool that can maybe spot some potential problems and lead to future, more exact investigations.
SHARE LAB 2016
VLADAN JOLER – RESEARCH, TEXT, DATA COLLECTING AND VISUALIZATION
ANDREJ PETROVSKI – RESEARCH, TEXT AND PROOFREADING
CONTRIBUTORS : KRISTIAN LUKIC AND JAN KRASNI
]]>
According to Bulgarian theoretician Alexander Kiossev, there is something that he calls “Self-colonizing metaphor”. He used this concept for explaining cultures subordinated to the cultural power of Europe and the West without having been invaded and turned into colonies in actual fact. He named this a hegemony without domination. As it all took place beyond colonial realities—military occupation, political dominance, administrative rule, and economic exploitation—social imagination had a key role to play throughout the process. In short, it could be described as colonisation with love.
Facebook is currently a major algorithmic colonial agent that might be indeed described as COLONIZATION with love.
Frontispiece of the book Leviathan by Thomas Hobbes (1651), Source : WIKIPEDIA
Understanding Facebook in the light of Foucault’s notion of modern power, we can begin to think of Facebook as an institution in which individuals are shaped and submitted to specific structures, which turns them from human beings into “self controlling subjects fitted for democratic capitalist society” (Lyon 2006). Exploitation would be a structural category that today also affects web 2.0 users, whose time, attention, personal data, talent/skills, education/training and materials are exploited. Given the structural character of exploitation, it would still be exploitation, even if people like it (Fuchs).
According to the recent research done by Happiness Research Institute from Copenhagen, in which they ask 1095 daily Facebook users to quit Facebook for one week they’ve come to interesting conclusions. Participants aged between 16 and 76 were asked before the experiment started how satisfied they felt, how active their social life was, how easy they could concentrate and how much they compared themselves to others. After the experiment was finished, the group that had abstained reported higher level of life satisfaction, better focus, feeling less lonely and sad. So, with the general relief experienced during the Facebook “vacation”, Facebook showed parallels with general feeling of working condition, a sense of “not wasting the time”, less stressed, more sociable, better life satisfaction.
New York University professors Helen Nissenbaum and Finn Brunton claim that today, approximately 10 years after social media were introduced, “The social cost of opting out has become so high that opting out is essentially a fantasy”. They propose different tactics in undermining asymmetrical power relations between proprietary platforms like Facebook and users. The deliberate addition of ambiguous, confusing, or misleading information interferes with surveillance and data collection. Difficulties for Facebook in precise targeting would be in that sense misleading information, links leading to strange or wrong websites, putting wrong data, several accounts and profiles, etc…
Context Collapse
In his essay, Autonomy and Control in the Era of Post-Privacy media, theorist Felix Stalder analyses a historical change in the perception and the role of privacy in the West. The sphere of privacy was citizen’s domain where the state does not have the right to interfere. Citizens’ obligation was to be loyal, to obey the rules, and to financially support state affairs through various kinds of taxation. The private law protected the subject from the eyes of the government and without special court permission under the assumption of criminal act, state officials were being forbidden to enter private property. Sure, the state security apparatus was illegally interested and engaged in gathering private data, but officially it was not allowed.
Stalder claims that the sacred sphere of privacy is rapidly changing and that users are not concerned with protecting the privacy realm anymore. With the rise of social media (and especially Facebook) we are witnessing massive amounts of private data, images that users voluntarily upload.
Before social media, social life had relatively separate areas. One area was one’s family, other was the professional circle, another were friends, circle around your hobby, etc. Sometimes these spheres of social life overlap, but mostly there was clear boundary between them.
 Source: Facebook
Source: Facebook
With social media and especially with Facebook these boundaries are blurring, so now all aspects of your social life are visible to all your social spheres. In sociology there is a term to describe that, the context collapse. Zuckerberg was praising this context collapse famously saying: “You have one identity; the days of you having a different image for your work friends or your co-workers and for the people you know are probably coming to an end pretty quickly”. Indeed Mark Zuckerberg looks identical when he is publicly talking during yearly Facebook venue for example, or when he is having interview, or when talking with president Obama or having precious time with his family.
But there is a recent trend, and Zuckerberg openly raised concerns about context restoration, which is a situation where more and more users do not give and share personal content, as it was previously the case. So users grew up and especially Facebook natives (teenagers) are concerned with it, thus moving to other platforms (like Snapchat for example). This means that Facebook slowly transfer itself into the public arena in a way that users are quite aware of the Facebook Panopticon. With rapidly growing precarity, job losses and automatization, Facebook would probably be the platform for performing professional potentialities and capabilities. Facebook would become a platform for professional networks with users who would act as private persons but this face would be a professional one. (Person, a mask in old greek). This means lowering the amount of private affairs (in narrower sense), like images of children, pets, private parties, etc. The latest acquisition of LinkedIn by Microsoft for 26 billion USD shows that the future battle will be a global battle for work with all means necessary, and that Facebook, Twitter, LinkedIn, (now with huge cash boost) together with growing Uber, Airbnb, Upwork, Behance etc will be megafactories for future proletariat and unemployed.
Human component in algorithmic factory
“viewer ought to be paid for watching tv”
Jean Luc Godard
Considering the growing global socio-economic disproportions and similarly growing importance of entrepreneurial tech companies that use collaborative platform model for their businesses there is a need to look at forgotten stakeholder – the producer of content, the human. Right now the producers of Facebook content are completely outside of Facebook financial environment.
Artist Laurel Ptak’s draws on the shifting condition from Fordism to post-Fordism with her ‘Wages for Facebook’, where she substitutes the word ‘housework’ for Facebook. Launched as a website in January 2014 at wagesforfacebook.com, it was immediately graced with over 20,000 views and rapidly and internationally debated on social media, message boards and in the mainstream, left and art press—clearly touching a collective nerve and beginning a broader public conversation about worker’s rights and the very nature of labour, as well as the politics of its refusal, in our digital age.
The privilege of sharing private data would be specialised for those who are self employed and who are not directly dependent on external employers. Facebook profile is becoming enlarged CV and proper balance between private and professional content would need to be carefully managed. This would have huge impact on the possibility of employment. As a user has unique profile it is not possible to model it according to the job demand description as it is the case with traditional job application with CV. For traditional job application, applicant usually highlighted skills and experiences that would fit to the needed specific concrete job description and remove those that are not suitable. But with the concept of a unique identity, those that are highly specialised and do not have complex multifaceted carrier would benefit more than those who have more general working experience. As already is the case, the narrow specialisation is already happening.
Great Depression in the United States
The huge gap between being socially isolated (not participating in Facebook) and maintaining proper profile would become highly stressful. Freelancers, self employed, unemployed and all those grey areas in between that now constitute the world of labour would need to spend more and more hours maintaining Facebook profiles offering in(directly) their expertise, experience, success stories, opinions and documentation of their works and activities, in similar fashion like sex workers in windows of red light districts.
All of this and much more has been recently developed by Facebook. According to Armin Arvidson Facebook with its algorithms might aim at becoming a sort of universal clearinghouse that deploys the logic of the derivative to determine the value of social relations outside of advertising markets, to provide analysis of attention, reliability and risk of social relations to wide range of operators like insurance companies, mortgage banks and employers.
Financialisation of everyday life
“Facebook will market you your future before you’ve even gotten there, they’ll use predictive algorithms to figure out what’s your likely future and then try to make that even more likely. They’ll get better at programming you – they’ll reduce your spontaneity. “
Douglas Rushkoff
“Orit Halpern’s book, Beautiful Data, suggests that we live not so much in worlds of pure simulation a la Jean Baudrillard (or Philip K. Dick), but instead, in a fascinated relation with flows of signals whose referential nature does not stop them from forming a “new landscape” for the viewer/user. In other words, the data is ostensibly about the world, but it upstages that world, becoming the primary object with which we interact (and thereby impoverishing the rest of experience). Something similar is suggested by Karin Knorr Cetina with her notion of “postsocial relations” carried on with the always-unfolding temporal objects that typically appear on screens, notably in the realm of finance. The stream of flow-objects constitutes a world, one you can dive into, wrestle with, and from which – in the case of financial traders – you dream of emerging victorious.” (Brian Holmes)
 Facebook drone – Aquila
Facebook drone – Aquila
As Facebook is investing in and developing infrastructure to cover all corners of the globe there is sound possibility that Facebook algorithms will be major agent in “financialisation of everyday life (Martin, R. 2002). In this sense Facebook would embody the “social logic of derivative” (Martin, R. 2013). Facebook was recently granted a patent for authorising and authenticating a user in applications for loans, which in practice means that someone’s Facebook behaviour would influence their prospect for housing for example. To escape Facebook will eventually be more difficult, as in recent announcement of Facebook, Facebook “will use cookies, “like” buttons, and other plug-ins embedded on third party sites to track members and non-members alike”.
What algorithmic governance (especially Facebook) in this sense means for users? It would potentially create auto-disciplinary society that would focus on targeting human anomaly detection and when detected it would calculate risks and decide on individual liquidities. Needles to say, in order to avoid personal scanning for loans, insurance, etc. those who have corporations with limited liabilities or similar incorporated entities would have huge advantages over “natural persons”. Sure, it is nothing new in long histories of “legal” and “natural” persons but the case with Facebook is an example of risk management in algorithmic financial capitalism.
So, the society might split in 2 categories. “Natural persons”, non-legal persons, who need to maintain radical self-discipline in the network (and Facebook) behaviour in order to avoid to be detected as “anomaly” by algorithm and thus jeopardise their general financial prospect; and those “legal-persons” who are firewalled by incorporated entities with limited liability.
Kristian Lukic
SHARE LAB 2016
References:
Kiossev, Alexander. The Self-Colonizing Metaphor. In Atlas of Transformation, JRP Ringier, tranzit.cz, 2010.
Oosthuyzen, Michelle. The Seductive Power of Facebook. Institute of Network Cultures blog, 2012 http://networkcultures.org/unlikeus/2012/05/24/the-seductive-power-of-facebook/
Fuchs, Christian. New Marxian Times! Reflections on the 4th ICTs and Society Conference “Critique, Democracy and Philosophy in 21st Century Information Society. Towards Critical Theories of Social Media”. 2012 http://triple-c.at.dd29412.kasserver.com/index.php/tripleC/article/viewFile/411/351 ,
Brunton Finn, Nissenbaum Hellen Obfuscation: A User’s Guide for Privacy and Protest. MIT Press, 2012.
Stalder, Felix. Autonomy and Control in the Era of Post-Privacy media
in Open! Platform for Art, Culture & the Public Domain, nr.19 , 2010. http://www.onlineopen.org/beyond-privacy
Ptak Laurel. Wages for Facebook. 2014 http://wagesforfacebook.com/
Holmes Brian. In a post on Nettime. 2016
https://www.mail-archive.com/[email protected]/msg03832.html
Rushkoff Douglas. In an interview in Guardian. Author of the interview Ian Tucker. February 12th 2016.
Randy, Martin. Financialization of Dayly Life. Temple University Press, 2002.
Martin, Randy. Knowledge LTD: Toward Social Logic of the Derivative. Temple University Press. 2015
]]>